‘Cátedra Nacional Esapista:Automatización e “ia”, una visión crítica.‘
Resumen
Este texto es una versión ampliada de la charla dictada en la cátedra nacional esapista el 26 de Noviembre del 2025. Los temas tratados en la charla son:
-
¿qué es automatizar? ¿qué es “i.a.”? ¿cuál es la relación entre esos dos conceptos?
-
¿si la ingeniería nos ha facilita la vida realmente necesitamos la carga cognitiva?
-
¿qué papel tiene el estado y lo público en todo esto?
Automatización e “i.a.”
Automatización
Son tecnologías que reducen la intervención humana en ciertos procesos predeterminando los criterios de decisión e incorporándo esos procesos en máquinas
¿cuál de los siguientes no es un ejemplo de automatización?
A. Google Maps
B. Olla a presión
C. Semáforo
La realidad es que los tres son ejemplos de automatización, con cierto nivel de complejidad.
”i.a.”
Guest y colaboradoras, en su artículo “Against the Uncritical Adoption of’AI’Technologies in Academia”1 presentan la siguiente figura que busca explicar cuáles son las tecnologías asociadas con chat-gpt. Explícitamente buscan hacer explítico el hecho de que la etiqueta “ia” lleva a la confusión.
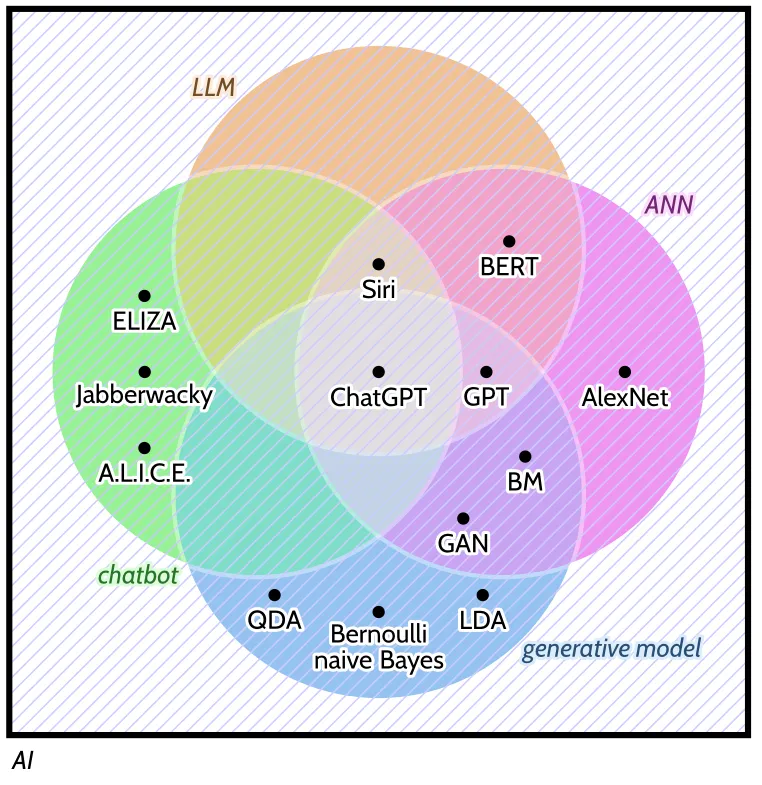
-
“i.a.” Es un término que no tiene una definición clara; el término se usa indistitnamente para hablar de un campo de estudio del conocimiento de la ciencia computaciona o un software.
-
ANN: Modelo matemático estadístico: Se basa en multiplicaciones matriciales y funciones no lineales. En su desarrollo hay una relación ténue con el cerebro; pero esa analogía también confunde, ya que se le puede atribuir más correlación entre lo que hace el modelo y lo que pasa en los cerebros de lo que realmente se puede demostrar.
-
ChatBot: Sistema ingenieril que parece conversar con usuarios usando texto o voz. Como ejemplos están ELIZA y A.L.I.C.E. Desde su incpeción se entiende que las personas tienden a asumir que tienen capacidades humanas de comunicación y cognición; pero esto está más relacionado con nuestra psíquis que con las capacidades mismas de estos sistemas. Los más modernos son ANN + reglas.
-
ChatGPT: ChatBot propietario propiedad de OpenAI. Como modelo de negocio no ha sido muy eficiente, ya que tiene acumulados 5 billones de deuda en 2024.
-
Modelo Generativo: Modelos estadísticos para la generación de texto o imágenes que se basan en modelos de la física. En su relación con los chatgptes es un término que se usa de manera inconsistente.
-
LLM: Modelos que capturan aspectos del lenguaje, usando un gran número de parámetros. Los chatbots modernos son LLMs que usan ANNs con una interfaz gráfica
Guest et al. 20251
¿cuál de los siguientes no es i.a.?
Dado que las empresas como openai buscan mejorar sus ingresos operacionales, tienen el incetivo de usar el término “ia” para hablar de cosas muy diferentes. Por ejemplo, hay toda un área del conocimiento de la ciencia que busca entender la forma en que las proteínas funcionan en el cuerpo. Las proteínas son macromoléculas, es decir, conjuntos grandes de átomos, entre ellas está el ADN. Su estudio es un campo activo del desarrollo científico, y una de las dudas que se tiene es: sabiendo cuál es la secuencia de átomos saber cómo es la estructura 3D. Aunque aquí no hay LLMs, ANNs, chatbots, se habla de que es “ia”. Se puede pensar que la razón de confundir los conceptos es el mercadeo, transferir el buen nombre de un proyecto que tiene altos estándares científicos a un producto que tal vez no tiene mucho en común.
| AlphaFold | Eliza | Google Search |
|---|---|---|
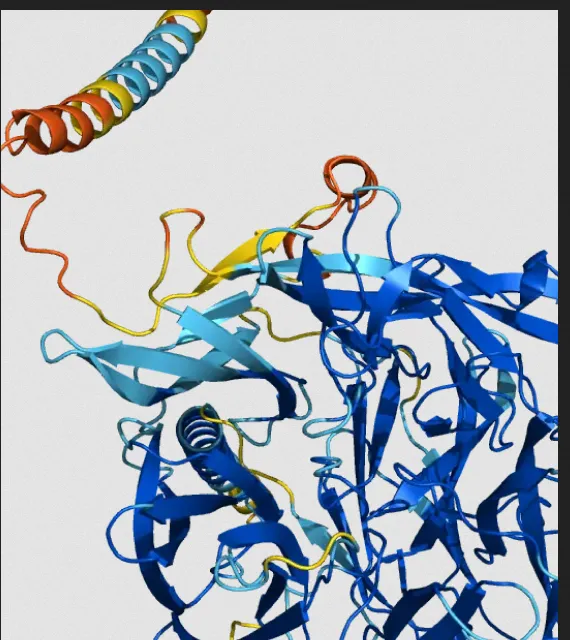 | 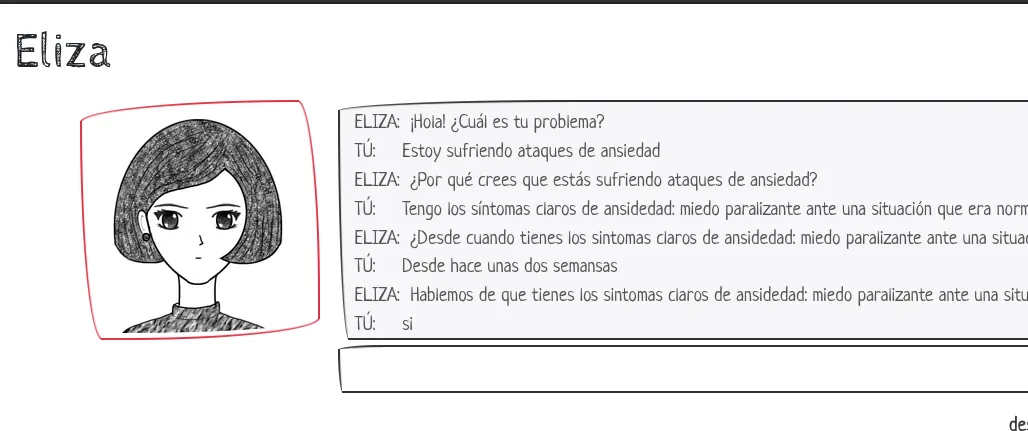 | 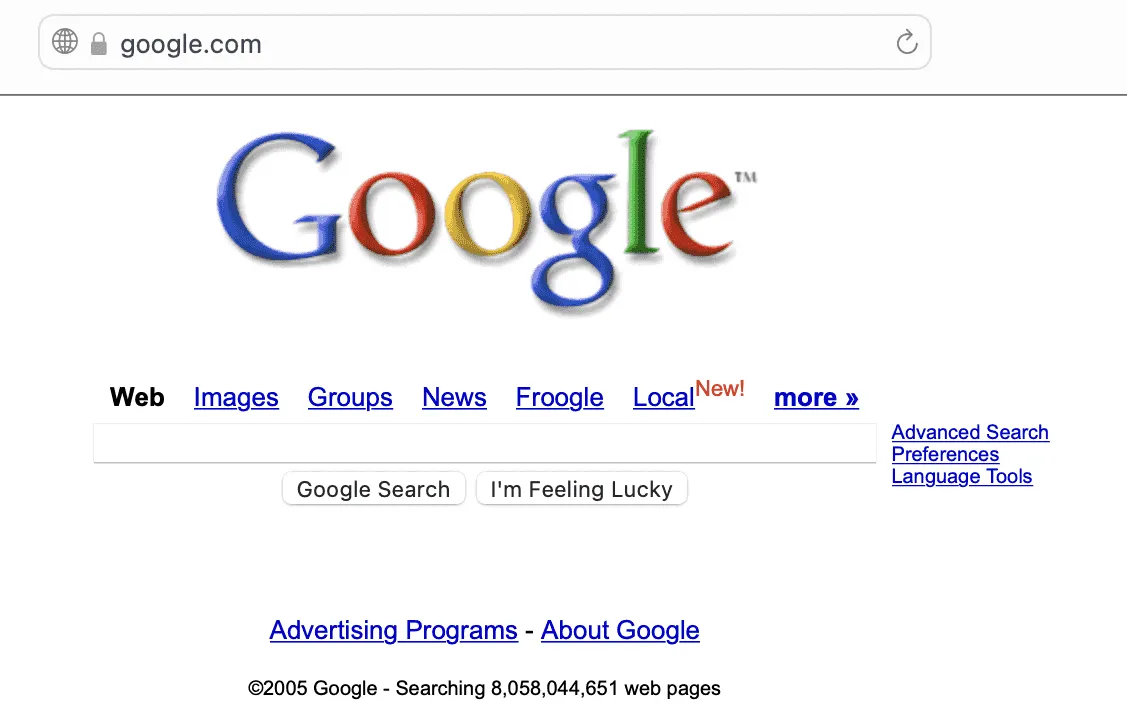 |
| Sistema de predicción de estructura desde la secuencia de proteinas | Un chatbot-terapeuta | Página de búsqueda en internet |
El algoritmo de búsqueda de Google también cae dentro de la categoría de “ia”, aunque incialmente se trató de una regla de evaluación de la calidad de la información muy sencilla.
Primer Mensaje Clave El término “i.a.” no es suficientemente preciso en la función pública. Mejor especificar qué queremos decir.
¿cuál es la relación entre “i.a.” y automatización?
Una vez se ha entendido que el término “ia” no tiene suficiente contenido semántico útil en un contexto académico (no dice mucho), es importante que pensemos realmente qué quieren las personas o las instituciones cuando indican que requieren “ia”. Una forma de verlo es entender que en algunos contextos las personas no están familiarizadas con el concepto de la automatización; y pueden llegar a confundir ambos contextos. Es decir, cuando decimos que …
-
¿queremos “i.a.” en la gestión de rutas en el transporte público? … realmente puede ser que lo que realmente queremos es automatizar la gestión de rutas. Y aquí no se necesitan modelos generativos, chatbots…
-
¿queremos “i.a.” en la categorización de datos de encuestas a la ciudadanía? … o lo que realmente queremos es automatizar la generación de reportes de encuestas? Aquí tenemos que tener cuidado, porque es posible que el uso de los modelos generativos realmente esté introduciendo información que no estaba en nuestro objeto de estudio. (habla******)
-
¿queremos “i.a.” en los servicios de atención a la ciudadanía? … o lo que queremos es automatizar la solución de preguntas comunes? Aquí tal vez es mucho más eficiente tener una página de FAQs. Que a una persona le va a costar más tiempo leerla que preguntarle al texto automatizado de google, pero esos 2 minutos de más se ven recompensados en que va a tener información veráz.
Segundo Mensaje Clave Se pueden automatizar servicios sin usar modelos estadísticos de lenguaje LLM o chatbots. Y a veces no es necesario automatizar!
La ingeniería ¿al rescate de la carga cognitiva?
En psicología el término “carga cognitiva” se define como el esfuerzo mental realizado para comprender un concepto o resolver un problema. En el esquema se muestra una información externa que las personas procesan mediante la memoria sensorial. Una parte de esa información se olvida inmediatamente. Como ejemplo, piense en la información de los sentidos que viene de sus pies al caminar… muchas veces ni siquiera tenemos conciencia de que esa información fue sentida por el cuerpo.
Luego está la información sensorial que llega a la memoria activa. Por ejemplo, un mensaje que nos llega del sistema de anunciso de transmilenio. La información llega a conciencia, pero cuando vemos que no es importante la olvidamos inmmediatamente.
Ahora está lo que queremos recordar. Por ejemplo, si usted quiere tener certeza de que recuerda el segundo mensaje clave de ésta charla, probablmenete vuelva atrás en éste texto y lo vuelva a leer. Con esta repetición buscamos que la información importante pase a estar a la memoria de largo plazo: la codificación. Y aún allí puede que lo olvidemos, por eso cuando queremos realmente aprender algo tenemos que volver a recordarlo “recuperación”.
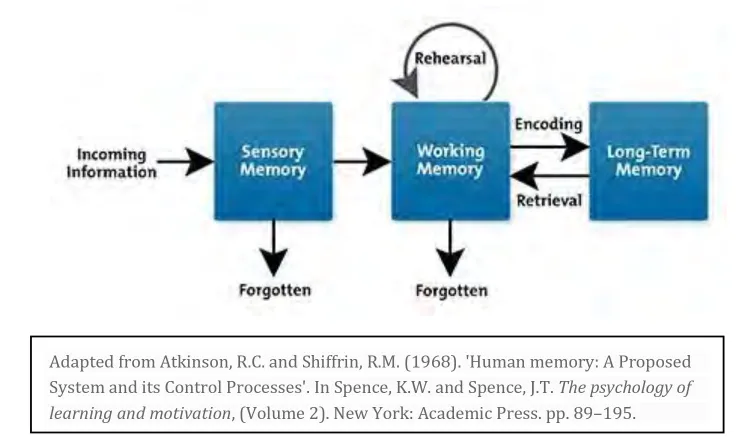
Ahora, este proceso también puede incluir una tercera parte, en la que las personas construyan nuevos conceptos a partir de los que ya tienen en memoria de largo plazo. Pensar. Es esta tarea la que buscamos cuando llevamos a cabo trabajo mental. La promesa de los sistemas “ia” es que nos liberarán del la carga cognitiva, de la necesidad de recordar procesar, etc.
Aquí surgen tres cuestiones.
-
Estos sistemas no tienen un proceso de aseguramiento de la calidad, luego los textos que generan son inferiores en calidad a lo que haría una persona. Esto úsualmente es costoso de comprender/reparar.
-
Cuando el producto es usado de todas formas, realmente estamos tercerizando el proceso de generación de conocimiento, luego estas compañías están en posición de extraer rentas (riqueza) que antes se quedaba en la sociedad (multiplicador social del salario, empleos informales, etc)
-
Dado que las empresas tienen ahora la capacidad de introducir mensajes los productos de conocimiento, hay un incentivo perverso para que modifiquen la información para su ventaja. (Grok hablando bien de Elno, Cambridge Analytica).
Tercer Mensaje Clave los gepetés no tienen la calidad de reemplazar a las personas, cuando lo hacen están siendo extractivistas cuando menos y posiblemente hasta propagandistas.
Los LLMs nos ayudan a hacer la investigación?
Una de las herramientas que se usa en investigación es Google Académico. Ahora (en el año 2025) presenta en su interfaz un botón de colores azul-violaceos con el texto “probar labs de académico”. Este color se relaciona con los sistemas “ia”, que aquí hemos llamado gepetés.

Una vez se hace click aparece un mensaje en gris que mencina la posibilidad de error.

Siendo explícitos no se trata de un error en el sentido académico, o hasta común de la palabra. Ya que “error” indica que hay una intención. En este caso el sistema generó un texto usando un método aleatorio. No decimos que el texto predictivo del celular “se equivoca”, es más preciso decir que “no adivinó, no predijo lo que queríamos decir”.
Texto leído en internet (no me han respondido a mi solicitud de hacer referencia a la autora, luego por ahora me reservo la referencia)
@AnarcoAmorosa@col.social: “Tomarse el tiempo que necesita una tarea de investigación es castigado ahora que la ia ‘puede hacer esa revisión de bibliografía’. Es increible que por querer pensar una quede como ineficiente.
El uso de los gepetés en el proceso de investigación va en contra del método científico.
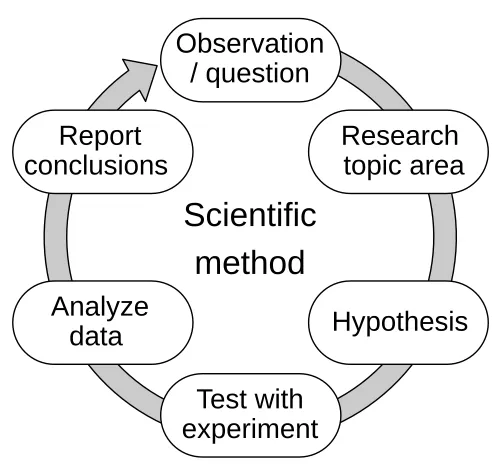
El método científico
| El Método Científico |
|---|
| Observación - Revisión literatura - Hipótesis - Experimentación - Análisis de datos- Conclusiones - Observación |
| Proceso para mejorar nuestros conocimientos |
LLMs propietarios remueven la reproducibilidad de la ecuación, ya que son sistemas cerrados, propietarios, basados en correlaciones estadísticas y para los que no hay forma de verificación.
Cuarto Mensaje Clave La investigación (ya sea consultoría, opinión, c. sociales, c. duras) debe ser reproducible. Los productos comerciales de “i.a.” no son reproducibles, luego no pueden garantizar la calidad requerida.
El papel del Estado
Desafíos 2
En un estudio reciente llevamos a cabo un estudio sobre la forma en la que los desafíos que enfrenta la “ia” se relacionan con principios éticos. Los desafíos que identificamos en la literatura son los siguientes.
| a.Manejo del sesgo (de entrenamiento) | b.Control del Problema | c.Privacidad (fugas de información) |
|---|---|---|
 |  |  |
| 3 | 4 | |
| Muchas veces existe una serie de sesgos en los datos de entrenamiento, que pueden perpetuar problemas de racismo, sexismo, etc. En un ejemplo famoso se pidió a uno de estos sistemas que generase una imágen de “médicos negros atendiendo a niños blancos”. El sistema generó la figura que se ve aquí, en la que se extiende el sesgo -erróneo- de que los médicos son señores blancos y la gente negra requeriría de ser salvada. | Existe una relación entre la responsabilidad de las acciones tomadas por las personas que tienen cargos públicos y los posibles daños que pueden llevar a la sociedad. En Colombia esto se media por el trabajo de “las ías” (contraloría, procuraduría, …). Esto lleva a que las personas actúen con cautela, para evitar consecuencias. | La forma en la que se generan los sistemas incluye siempre el uso de cantidades ingentes de información, que se sistematizan en una serie de matrices que correlacionan diferentes términos. No es posible entrenar con pocos datos, y los LLMs siempre tendrán la información de entrenamiento. Esto lleva a que no sea técnicamente posible asegurar que la información de entrenamiento no se filtrará o que las empresas no usarán su información para entrenar futuros sistemas. |
| e.Propiedad Intelectual | f.Impacto Ambiental |
|---|---|
 |  |
| 5 | 6 |
| Las empresas han sido claras en que su modelo de negocio sólo funciona si se les permite utilizar información que tiene reserva de propiedad intelectual para generar sus modelos.Es decir, la “ia generativa” sólo es rentable si pueden piratear toda la información de la humanidad. Lo que resulta una suerte de robin hood al revés, en que las compañías gigantes deben robar a creadores individuales para existir. | Las empresas gigantes que trabajen en IA lentamente han borrado sus compromisos medioambientales, dado que las necesidades ambientales de estos sistemas son tan grandes en términos energéticos o de agua potable; que ha borrado los avances que habían hecho estas empresas en sus metas de reducción de gases efecto invernadero. |
Principios Éticos 7
Estos desafíos se reqlacionan con una serie de principios éticos, que varían entre los diferentes autores. En nuestro trabajo hacemos un análisis sobre la percepción que tienen las personas que trabajan en el sector público o en la academia en Colombia sobre la forma en la que se están cumpliendo (o no) estos principios éticos.
Hablamos de:
-
Inteligibilidad: “hay claridad en los funcionarios públicos sobre cómo funcionan esos sistemas”
-
Responsabilidad: “hay claridad sobre quién es responsable por el uso de la IA”
-
No discriminación: “se propende por eliminar la discriminación garantizando el acceso igualitario a la IA”
-
Autonomía: “no se afecta la autonomía de decisión de las personas”
-
Bienestar: “se provee el bienestar, incluyendo aspectos de dignidad, seguridad y/o sostenibilidad”
-
Seguridad: “hay prácticas para el uso adecuado de la información”
Cuarto Mensaje Clave La planficación del uso de cualquier herramienta computacional (incluyendo ia) en el sector público debe seguir los principios de: inteligibilidad, responsabilidad, no discriminación, autonomía, bienestar y seguridad.
(esto puede querer decir que hay que frenar su adopción, hasta que no se puedan usar sistemas que se puedan instalar localmente)
Notas a Pie
Footnotes
-
Guest, O., Suarez, M., Müller, B., van Meerkerk, E., Beverborg, A. O. G., de Haan, R., … & van Rooij, I. (2025). Against the Uncritical Adoption of’AI’Technologies in Academia. ↩ ↩2
-
Marr, 2021 ↩
-
https://www.npr.org/sections/goatsandsoda/2023/10/06/1201840678/ai-was-asked-to-create-images-of-black-african-docs-treating-white-kids-howd-it- ↩
-
La imagen se cita como extraída de un manual de entrenamiento de 1979 de IBM, aunque no hay evidencia fuerte: https://simonwillison.net/2025/Feb/3/a-computer-can-never-be-held-accountable/ ↩
-
https://copyrightalliance.org/takeaways-senate-hearing-ai-copyright-piracy/ https://www.salon.com/2024/01/09/impossible-openai-admits-chatgpt-cant-exist-without-pinching-copyrighted-work/ ↩
-
https://news.mit.edu/2025/explained-generative-ai-environmental-impact-0117 https://www.tomshardware.com/tech-industry/google-quietly-removes-net-zero-carbon-goal-from-website-amid-rapid-power-hungry-ai-data-center-buildout-industry-first-sustainability-pledge-moved-to-background-amidst-ai-energy-crisis ↩
-
Gabriel Villalobos Camargo y Carlos Hernán Fajardo Toro. Perspectivas desde la academia y la función pública sobre las implicaciones éticas de la inteligencia artificial En Tecnologías de la información y la comunicación en la administración pública isbn 978-958-609-000-0 https://libros.esap.edu.co/index.php/omp/catalog/book/79 ↩