Unir bases: concatenar series
Concatenar
Si y son objetos organizados, concatenar y consiste en crear un nuevo objeto con los registros de y ; organizados secuencialmente.
Ejemplo
Dados:
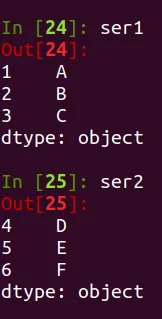
ser1 = pd.Series(['A', 'B', 'C'], index=[1, 2, 3])
ser2 = pd.Series(['D', 'E', 'F'], index=[4, 5, 6])
¿Qué tipo de estructura de datos son?
¿Cómo espera que se muestren en Python ?
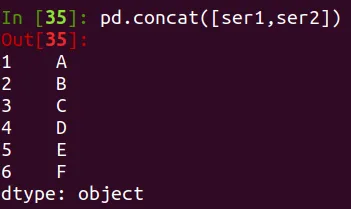
Concatenar las Series
pd.concat([ser1,ser2])
Si las series son las siguientes:
Se pueden concatenar de la siguiente manera:
DataFrames con las mismas variables
Concatenar dos DataFrames. Los definimos (usualmente usted los lee de un archivo):
df1=pd.DataFrame([['A1','B1'],['A2','B2']],columns=['A','B'],index=[1,2])
df2=pd.DataFrame([['A3','B3'],['A4','B4']],columns=['A','B'],index=[3,4])
Los concatenamos con el comando pd.concat:
![Impresión de pantalla. El comando es dfc=pd.concat([df1,df2]). El resultado es una tabla con las columnas A y B, y su primer registro es A1,B1](/_astro/dfconcat.B6cnkeeD_ZNCjUu.webp)
Usualmente no nos interesa preservar el índice, luego usamos la opción
ignore_index=True, para que se reasigne el índice:
![Impresión de pantalla. Primero está la instrucción pd.concat([df1,df2],ignore_index=True), seguido por una tabla con las variables A, B, y cuyo primer registro es A1,B1.](/_astro/dfcignoreindex.GUUm5PUa_Z1Y6mLM.webp)
DataFrames con diferentes variables
Concatenar dos DataFrames
Los definimos (usualmente usted los lee de un archivo):
df5=pd.DataFrame([['A1','B1','C1'],['A2','B2','C2']],columns=['A','B','C'],index=[1,2])
df6=pd.DataFrame([['B3','C3','D3'],['B4','C4','D4']],columns=['B','C','D'],index=[3,4])
Imprímalos. ¿Qué variables tiene df5?
¿Qué variables tiene df6?
Podemos usar el atributo .columns, así: `df5.columns’.
¿Que cree que puede pasar al concatenar los dos DataFrames?
Concatenar Uniendo los conjuntos de variables
El DataFrame, mezcla de df5 y df6, tiene todas las variables (aquí ,,,.):
pd.concat([df5,df6],join='outer')
‘outer’ es el valor por defecto de join, es equivalente a
pd.concat([df5,df6])
Se obtiene lo siguiente:
![Impresión de pantalla. Primero está la instrucción pd.concat([df5,df6]), cuyo resultado es una tabla con las variables A,B,C,D. El primer registro es A1,B1,C1,NaN. La segunda instrución es pd.concat([df5,df6],join='outer'), el resultado es una tabla con las variables A,B,C,D. El primer registro se sde nuevo A1,B1,C1,NaN](/_astro/outerconcat.BXAb9YkG_Z2re3RI.webp)
Intersectando conjuntos de variables
El DataFrame, mezcla de df5 y df6, tiene sólo las que están en ambos \pause (en este caso, y .):
![Impresión de pantalla de código. Está la instrucción pd.concat([df5,df6],join='inner') y luego el resultado de esa instrucción, que es una tabla con las variables "b" y "C".](/_astro/innerconcat.DTb2L_sP_ZMQCYm.webp)
Combinar DataFrames: Merge y Join
Merge: Uno a Uno
Supongamos que se tienen los siguientes conjuntos de datos (organizados en dataframes):
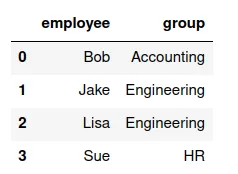
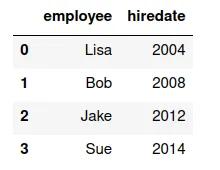
un(valor de la variable)-a-un(valor de la variable)
Un merge uno a uno consiste en crear un nuevo conjunto de datos (dataframe, tabla) que tenga los valores del primero apareados con los valores de la segunda.
¿Cuáles son las variables de df7?
¿Cuáles son las variables de df8?
Si queremos un DataFrame que tenga las variables
'employee','hiredate','group', debemos mezclar, aparear, df7 y
df8.
merge
El comando mergede Python aparea automáticamente si hay una variable
compartida en los dos DataFrames. El código sería el siguiente. Primero generamos el conjunto de datos df7 y el conjunto de datos df8:
df7 = pd.DataFrame({'employee': ['Bob', 'Jake', 'Lisa', 'Sue'],'group': ['Accounting', 'Engineering', 'Engineering', 'HR']})
df8=pd.DataFrame({'employee': ['Lisa','Bob','Jake','Sue'],'hiredate': [2004,2008,2012,2014]})
Y luego hacemos el merge:
dfm = pd.merge(df7,df8)
print(dfm)
El resultado es el siguiente:
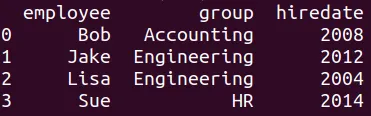
Tenga en cuenta que:
-
No importa que los registros no estén en el mismo orden
-
Usualmente se descarta el índice.
Merge: Muchos (valores de la variable) a Un (valor de la variable)
Vamos a trabajar con el conjunto dfmque habíamos generado
anteriormente, y un nuevo conjunto df9:
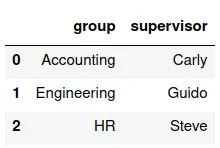
¿cuál sería el código para asignar los datos de esa tabla a la variable df9?
Muchos-a-Uno
Se trata de unir dos DataFrames, en el caso en que uno de ellos
tiene registros que repiten el mismo valor de la variable.
En éste caso, ¿Qué variable de dfm tiene valores repetidos en
diferentes registros?
merge
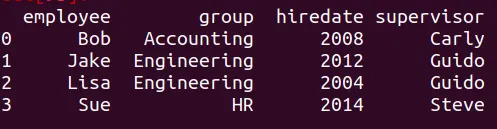
Al mezclar dfm y df9 Python crea un nuevo conjunto de datos, para
el cual a cada registro se le asigna la variable supervisor,
apareando de las dos tablas anteriores. Hagamos el merge, asignémoslo
a la variable df9, e imprimamos el resultado de la operación.
dfm3 = pd.merge(dfm,df9)
print(dfm3)
El resultado es el siguiente
Merge: Muchos a Muchos
Supongamos que tenemos los siguientes conjuntos de datos.
Primero df7 es:
Y df10 es:
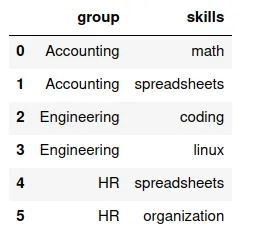
Éscriba el código para generar estas dos tablas.
¿Qué variable comparten los DataFrames?
¿Que espera que pase al mezclarlos?
Muchos-a-Muchos
Se trata de un apareamiento muchos-a-muchos porque en ambos dataframes hay variables que tienen registros repetidos.
merge
El código para mezclarlos es:
dfm2 = pd.merge(df7,df10)
Y se puede imprimir el resultado con:
print(dfm2)
En este caso el resultado es:
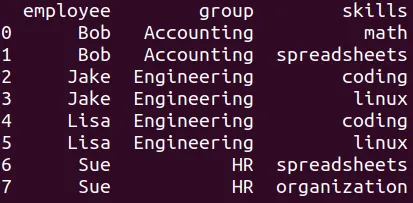
Por cada valor de skills hay un registro, así se repitan los valores
de las varriables employee y group.
Ejercicio
Pregunta
Tenemos dos archivos con información de la interacción de personas con el Estado. Queremos determinar si las personas pueden participar en un concurso. En la primera base df1 tenemos número de cédula y tipo de trámite que quiere realizar. En la segunda base, df2, tenemos número de cédula y una variable que indica si la persona tiene o no sanción disciplinaria.
¿Qué operación/operaciones haría para generar una base que indique si las personas que quieren participar en el concurso tienen o no sanción disciplinaria?
- Filtrar por valores en
df1, Concatenar las dos bases. - Filtrar por valores en
df2, unir con merge las dos bases. - Filtrar por valores en
df1, unir con merge las dos bases. - Filtrar por valores en
df2, Concatenar las dos bases.
Casos Especiales
Renombrar Variables
Si queremos renombrar las variables de un DataFrame, podemos usar el
método .rename()
Por ejemplo, si tenemos el siguiente DataFrame, llamado df12:
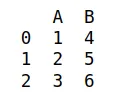
Podemos querer cambiar el nombre de las variables (mayúscula a minúscula). Se puede hacer así:
df12.rename(columns={"A": "a", "B": "b"})
¡Atención! Por defecto la función devuelve un nuevo
DataFrame. Para alterar el que tenemos, use la opción inplace.
df12.rename(columns={"A": "a", "B": "b"}, inplace=True)
Es decir:
![Impresión de pantalla. Primero está la instrucción para generar df12: df12=pd.DataFrame({"A":[1,2,3],"B":[4,5,6]}). Luego está la instrucción para renombrar, df12.rename(columns={"A": "a", "B": "b"}).](/_astro/ejemplorename.C_EyAycQ_ZEJKfe.webp)
Especificar la columna a usar de clave para mezclar
Si los DataFrames comparten diversas variables, podemos usar la
opción on para especificar cuál variable usar como clave para
mezclar.
EJEMPLO
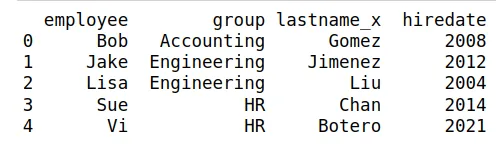
Si el df13 es el siguiente:

Y df14 el siguiente:
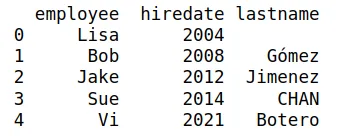
¿qué variables son comunes entre los dos DataFrames?
Si hacemos el merge debemos especificar cuál de las variables se usa
para mezclar. Por ejemplo puede ser employee. La instrucción:
pd.merge(df13,df14,on='employee')
El resultado es una nueva base, que usa como llaves la columna
employee y tiene las variables de los dos conjuntos de datos
anteriores. Como tenemos dos veces la variable lastnamem, una por
conjunto, aquí nos saldrá repetida, es decir lastname_x es la del
primer conjunto y lastname_y la del segundo.
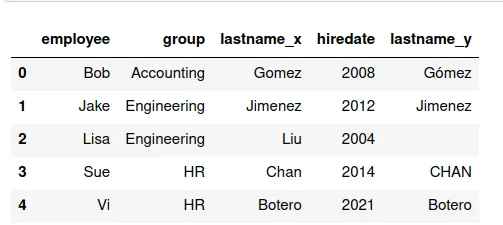
De nuevo, se puede remover la variable duplicada con el método .drop:
df15 = pd.merge(df13,df15, on="employee")
df15 = df15.drop("lastname_y", axis=1)
print(df15)
Produce la siguiente tabla:
Especificar columnas diferentes en DataFrames
Podemos especificar diferentes variables para cada DataFrame. Aquí
el primero será left_on y el seguido será right_on.
Supongamos que tenemos el df11:
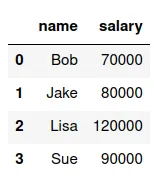
Una forma de ingresar este DataFrame es el siguiente código:
df11=pd.DataFrame({'name': ['Bob', 'Jake', 'Lisa', 'Sue'],'salary': [70000, 80000, 120000, 90000]})
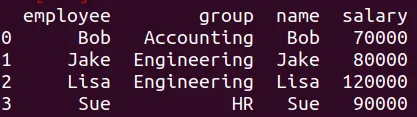
El df7 es el que ya teníamos:
Los DataFrames df11 y df7 tienen variables con la misma
información pero diferente nombre de variable. Podemos mezclar, pero
debemos especificar cuáles son las variables. La instrucción es:
pd.merge(df7,df11,left_on="employee",right_on="name").drop("name",axis=1)
Se obtiene la siguiente tabla:
Inner - Outer - Left - Right
Volvamos a pensar en que pasa cuando existen valores de los registros
que no se encuentran en ambos DataFrames.
Tomemos los siguientes conjuntos de datos, llamados df13:
y df16:

¿Qué cree que pasa si mezclamos estos dos dataframes?
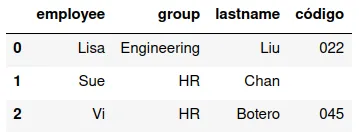
inner
Intersecta los conjuntos, es decir, produce un DataFrame que tiene
sólo registros que tienen valores de variables en ambos DataFrames:
pd.merge(df13,df16,how="inner")
Devuelve un DataFrame que sólo tiene los valores para los cuales la llave está en ambos.
outer
Une los conjuntos, es decir, produce un DataFrame que tiene todos
registros que tienen valores de variables en alguno de los
DataFrames. Los valores faltantes los llena con NAs. En este
ejemplo la instrucción sería:
pd.merge(df13,df16,how='outer')
Y se obtiene:
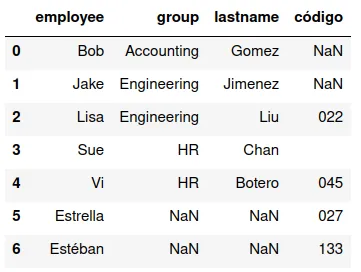
Merge a la izquierda (primer DataFrame) y a la derecha (segundo)
left
Si hay dos conjuntos de llaves, y difieren en algunos valores de la
variable, se puede usar los registros que corresponden a los valores
de la variable del primer DataFrame.
En el ejemplo que hemos trabajado, la instrucción sería:
pd.merge(df13,df16,how='left')
Y produciría el siguiente conjunto de datos:
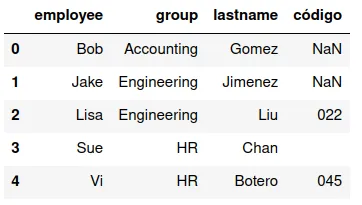
right
Si hay dos conjuntos de llaves, y difieren en algunos valores de la
variable, se puede usar los registros que corresponden a los valores
de la variable del segundo DataFrame.
pd.merge(df13,df16,how="right")
Y produciría el siguiente conjunto de datos:
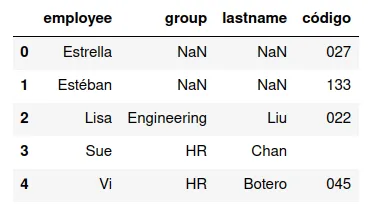
Ejercicio
Mezclar las bases de datos del DANE de Nacimientos
Vamos a trabajar con la base que ya habíamos bajado anteriormente (Nacimientos para el año 1998), además de una nueva.
- Intente buscar en internet el enlace para Estadísticas Vitales 2021
- OK, éste es el enlace: https://microdatos.dane.gov.co/index.php/catalog/775/get-microdata
- Descargue - Organice - Renombre - Registre los cambios
- Cargue ambos
DataFrames, tanto el del 98 que ya había usado, como éste del 21. En Python llámelosdatos98ydatos21 - Imprima los nombres de variables (columnas) de ambos
DataFrames. ¿Qué similitudes encuentra? ¿Qué diferencias encuentra? - ¿cómo averiguaría cuántos registros hay en el 98 y cuantos en el 21?
- Si queremos un
DataFramepara el cual sólo vamos a comparar el peso de neonatos entre el 98 y el 21, ¿cuál es la forma más sencilla de hacer eseDataFrame? - Si queremos comparar las variables Edad de la Madre, Edad del Padre, Peso al Nacer, talla, entre los dos años; y para eso hacemos un nuevo
DataFrame, ¿que deberíamos hacer?