Medición de Datos
Tipos de Variables
- contínua números reales en un rango. Ejemplo la estatura.
- discreta numeros enteros en un rango. Ejemplo la edad.
- Categórica Ordinal las observaciones toman etiquetas organizables.
- Categórica Nominal Las observaciones tienen etiquetas no organizables.
Implementación en Python
-
Números Enteros Cómo 42. (En matemáticas son entero )
1 + 1 5*8(python asume que son enteros)
-
Números Flotantes Como 2.85 (En matemáticas son los racionales )
9/2Python entiende que estamos dividiendo flotantes. ¿cuál es el resultado?
-
Texto En español: (Después hablaremos de la codificación, por ahora recuerde éstas letras: UTF-8.)
'Estás en lo cierto' -
Lógica Se representan como
True,False, 1o0. -
Error Operaciones no disponibles o incompatibles.
#VALUE!o#¡VALOR! -
Las variables categóricas, tanto ordinal como nominal, se representancomo texto o variables lógicas.
Ejercicio
- Clasifique los siguientes variables como número, texto o valor lógico.
a. 'palabra'
b. 3.5
c. 3,5
d. True
e. 1
f. 1/2
g. 'uno'
Conceptos Estadísticos
Video de ésta sección: https://youtu.be/45V4GQMG75c
-
Universo: Conjunto de ‘Individuos’ Objeto de Investigación. Ejemplos:
- Ríos en una vertiente
- Habitantes de una zona.
- Registros de datos de una entidad
-
Observaciones: Cada uno de los valores de la variable que se registra para uno de los individuos. Se representa por:
-
Población: Conjunto de mediciones de una variable en cada ‘individuo’. Su tamaño es . Ejemplos:
- Caudal en punto medio. Longitud de los tramos navegables. Número de especies aprovechables
- Último grado cursado. Lugar de vivienda. Edad.
- Fecha y hora. Longitud en palabras. Tipo de solicitud.
-
Muestra: Subconjunto representativo de la población. Sus características son similares a las de la población. Su tamaño es .
-
Parámetro: Característica de la población de referencia. Ej. promedio , proporción , total, varianza , distribucionalidad. Usualmente son desconocidos, obj. de investigación.
-
Estadística (estadígrafo): Cálculos sobre los datos de la muestra, que estiman los parámetros de la población. Ej. promedio muestral , varianza muestral , y proporción muestral ).
Medidas de tendencia central
- Promedio Aritmético
- (sobre la muestra )
- (sobre la población )
-
Mediana : Aprox. la mitad de las observaciones son mayores a la mediana.
-
Moda: Es el dato que se repite más veces en una muestra.
Ejercicios
Un promedio sobre un conjunto pequeño de datos
Supongamos que tenemos la siguiente muestra de un conjunto de datos:
x = [1,5,1,1,1]
Vamos a hacer cálculos sobre ésta muestra, sin usar las funciones estadísticas del softare). Halle los valores de las medidas de tendencia central: moda, mediana, media.
Ahora un promedio sobre un conjunto más grande
Comencemos por generar un conjunto de datos.
import random as ran
ran.seed(8)
lista = [ran.choice([1,2,3,4,5,6]) for x in range(100)]
No es necesario que entendamos a profundidad ese código ahora. Pero le invito a que intente describir qué obtuvimos con éstas instrucciones antes de leer mi explicación.
.
.
.
OK, tenemos una lista de 100 números, donde los elementos son los números enteros del 1 al 6, elegidos al azar.
Ahora, usando Python, intentemos calcular las medidas de tendencia
central.1
Medidas de variabilidad
Videos de ésta sección en: https://youtu.be/TnChXWqAQN0
-
Rango: valor máximo menos el valor mínimo
-
Varianza
-
Varianza de la población:
-
Varianza de la muestra:
-
-
Desviación estándar
-
Desviación estándar de la población
-
Desviación estándar de la muestra
-
Coeficiente de variación: Tamaño de la dispersión relacionada con el tamaño del promedio.
-
Ejercicios
Sobre la muestra pequeña
Supongamos que tenemos la siguiente muestra de un conjunto de datos:
x = [1,5,1,1,1]
Vamos a hacer cálculos sobre ésta muestra, sin usar las funciones estadísticas del softare. Halle los valores de las medidas de variabilidad: Rango, Varianza, Desviación estándar.2
Sobre el conjunto más grande
Ahora tome de nuevo la lista que habíamos calculado anteriormente y calcule los estadísticos de variabilidad.3
Medidas de Localización
Percentiles Muestrales
Puede ver el libro de González páginas 124 a 133.
El percentil muestral es un valor mayor o igual que al menos por ciento de los datos y menor que al menos por ciento de los datos.
La posición del percentil , es: . Los datos ordenados son:
El valor es una interpolación lineal entre los dos valores. Si la parte entera de la posición es y la fraccionaria es , entonces va entre y , así:
Ejemplo, tiempos de espera
En una ventanilla de servicio al cliente se tienen los siguientes tiempos de espera en minutos:
12 19 13 3 7 3 3 3
7 7 4 6 10 9 21 12 3 10 3 4
Si los ordenamos tenemos:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
3 3 3 3 3 3 4 4 6 7 7 7 9 10 10 12 12 13 19 21
Calcule el
Respuesta: primero necesitamos la posición y luego el valor:
-
Posición: , En este caso tenemos una parte entera de y una parte fraccionaria
-
Valor:
Medidas de forma y Simetría
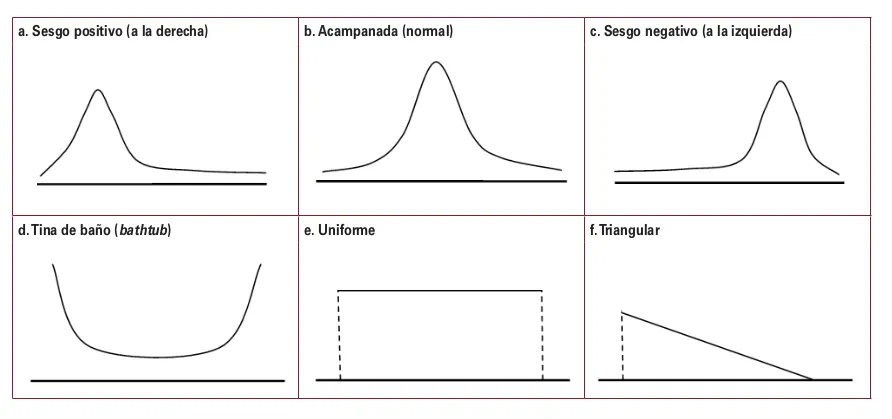
Coeficiente de Simetría
- : sesgo a la derecha
- : distribución simétrica
- : sesgo a la izquierda
En Excel
COEFICIENTE.ASIMETRIA
En LibreOffice
COEFICIENTE.ASIMETRIA.P
Ejemplo
De nuevo, trabajaremos con un conjunto grande de números que vamos a generar en Python. Llamémosle dist1:
import numpy as np
np.random.seed(22)
dist1 = np.array([np.random.poisson(2) for x in range(1000)])
En Python podemos calcular la asimetría con la función skew de la librería scipy.
import scipy.stats as stats
import statistics as st
asimetria = stats.skew(dist1)
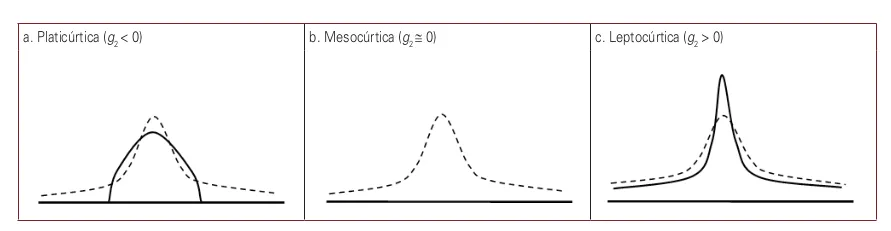
Curtosis
- menos apuntada que la distribución normal
- tan apuntada como la distribución normal
- más apuntada que la distribución normal
Solución ejercicios
Footnotes
-
Para el promedio se puede hacer la suma, contar los elementos, y luego hacer la división:
suma = sum(lista) nelementos = len(lista) promedio = suma/nelementos print(promedio)También se podría hacer con una función. Por ejemplo, usando la librería
statistics:import statistics as st promedio = st.mean(lista) print(promedio)Para la mediana podemos ordenar la lista y luego tomar los elementos de la mitad. En este caso el número de elementos es par, entonces tomamos el y el siguiente:
lista.sort() elementon = lista[int(nelementos/2)] elmentonmasuno = lista[int(nelementos/2)+1] mediana = (elementon + elementonmasuno)/2 print(mediana)Para la moda podemos imprimir los valores y contar las repeticiones:
print(lista)O usando la librería:
↩moda = st.mode(lista) print(moda) -
Primero el rango. En este caso el valor máximo es 5 y el mínimo es 1, luego la resta es 4. Si queremos hacerlo con un código:
maxx = max(x) minx = min(x) rango = maxx - minx print(rango)Para la varianza podemos hacer dos cálculos. Primero podemos usar la fórmula directamente, restándo a cada elemento de la lista el promedio de la lista, elevando los resultados al cuadrado y finalmente sumando:
valores = np.array(x) promedios = np.mean(x)*np.ones(len(x)) restas = valores - promedios restascuadrado = restas**2 sumarc = np.sum(restascuadrado) varianza = sumarc/(len(x)-1) print(varianza)Podemos comparar usando el comando
variancede la libreríast, que corresponde a la varianza muestral:print(st.variance(x))Luego, para la desviación estándar podemos calcular la raíz de la varianza:
print(varianza**0.5)o usar el comando
stdevde la librería statistics:
↩print(st.stdev(x)) -
En este caso se puede usar una estratégia (y un código) similar al del ejercicio anterior. Sabemos que el conjunto tiene valores entre el 1 el 6, por lo tanto el rango será 5. O, de nuevo:
maximo = max(lista) minimo = min(lista) rango = maximo - minimo print(rango)Para la varianza y la desviación estándar son cálculos similares a los del apartado anterior. ↩