Análisis de varianza
- Se busca comparar tres o más grupos (ej. 4 medicamentos, 4 dosis, etc)
- ¿cómo comparar promedios, si hay dispersión entre los grupos? efecto de la varianza:

- varianza dentro del grupo, vs. varianza entre los grupos.
Elementos del diseño de experimento
Experimento: situación planeada y controlada. Prueba o serie de pruebas para identificar causas
- Unidades Experimentales: objetos a medir (ej. pacientes, registros públicos, etc)
- : Variable dependiente a ser analizada.
- : Variables independientes que afectan la respuesta.
- : Grado de intensidad de un factor
- : Combinación de factores a diferentes niveles
Ejemplo:
Tomemos la siguiente situación problemática. Estudiar el crecimiento de una planta, en función de tres variedades de fertilizante y de cuatro tipos de suelo.
- Unidades Experimentales Planta
- Longitud de Crecimiento
- A: fertilizante, B:Suelo
- tres para A: A1,A2,A3;cuatro para B: B1,B2,B3,B4
- Combinaciones de A y B
ANOVA a una vía
Un factor, niveles, buscamos comparar los promedios de una variable en los grupos. Se seleccionan muestras aleatorias independientes de las poblaciones (diseño completamente aleatorizado).
Supuestos
- La variable dependiente se distribuye normal en cada grupo
- La varianza es igual entre poblaciones
- Las Observaciones son independientes.
Hipótesis
- los grupos tienen el mismo promedio (no hay efecto del tratamiento)
- un produce efecto diferente.
Ejemplo 0: Dados
Tenemos 12 dados de 6 caras y 6 dados de 4 caras. Si hacemos 3 grupos de la siguiente forma:
| D4 | D4 | D4 | D4 | D4 | D4 |
| D6 | D6 | D6 | D6 | D6 | D6 |
| D6 | D6 | D6 | D6 | D6 | D6 |
Si lanzamos los dados y generamos una tabla, ¿esperamos una diferencia en el promedio entre grupos?
Si los 3 grupos son:
| D4 | D4 | D6 | D6 | D6 | D6 |
| D4 | D4 | D6 | D6 | D6 | D6 |
| D4 | D4 | D6 | D6 | D6 | D6 |
Si lanzamos los dados y generamos una tabla, ¿esperamos una diferencia en el promedio entre grupos?
¿Hay más diferencia entre promedios de los grupos rojos (1,2,3) o entre los grupos azules (4,5,6)?
Hipótesis
- los grupos tienen el mismo promedio (no hay efecto del tratamiento)
- un produce efecto diferente.
, la -ésima observación del
| G | G | … | G |
|---|---|---|---|
| … | |||
| … | … | … | … |
| … |
| Total | … | ||||
|---|---|---|---|---|---|
| Media | … |
: es la suma del
es el promedio del
es la suma de todos los grupos
es el promedio de todos los datos
Modelo
Suma de Cuadrados Total
O variación total en el experimento:
es la distancia de cada medición al promedio. Luego la es la suma de los cuadrados de las distancias al promedio.
Ejemplo 1
Si tenemos Los siguientes grupos:
| G1 | G2 | G3 | |
|---|---|---|---|
| 8 | 14 | 10 | |
| 7 | 16 | 12 | |
| 9 | 12 | 16 | |
| 13 | 17 | 15 | |
| 10 | 11 | 12 |
Para hallar la suma de cuadrados total calculamos total y media por grupo:
| G1 | G2 | G3 | |
|---|---|---|---|
| Total, | 47 | 70 | 65 |
| Media, | 9.4 | 14 | 13 |
Y calculamos la suma de todos los datos y su promedio:
Ejemplo 2 (KA), SST
De Khan Academy, en el enlace: https://youtu.be/tH01ocwZGkQ?si=C7f4ZRoxIGunajC8
Suma de cuadrados entre tratamientos y dentro de tratamientos
La expresión para SST se puede modificar haciendo algo de álgebra (como lo muestra el profesor Contento en su libro del año 2019). Después de ésto se llega a :
Donde: es la suma de cuadrados total que ya conocemos, y
-
que se define como es la variabilidad debida a diferentes tratamientos, suma de cuadrados entre tratamientos.
-
que se define como es la variación de los sujetos que pertenecen a un tratamiento, es decir la suma de cuadrados dentro de tratamientos. LLamado también Error.
Volviendo al…
Ejemplo 1
Tenemos que:
Ejemplo 2
Para calcular SCTr y SSE para el ejemplo 2, siga el enlace: https://www.youtube.com/watch?v=l_VHVIF7_cs
Grados de Libertad
Recordemos que estamos interesados en identificar si existe variabilidad entre diferentes grupos. Ahora, como necesariamente habrá más variabilidad si hay más grupos y más datos, es necesario tener en cuenta los grados de libertad.
-
Grados de libertad de los tratamientos: , será el número de tratamientos menos uno.
-
Grados de libertad entre tratamientos: será el número total de datos menos uno.
-
Grados de libertad dentro de los tratamientos: es la resta de los dos anteriores.
Cuadrados medios
Con los grados de libertad se calculan los cuadrados medios de variación
-
, son los cuadrados medios tratamientos
-
son los cuadrados medios de los tratamientos.
Prueba de Hipótesis
Si el tratamiento no funciona, los promedios serán todos iguales. Si el tratamiento funciona habrá uno de ellos que es diferente. Entonces podemos lanzar las hipótesis:
-
Entonces {La variación entre grupos es similar a la variación dentro de grupos . -
, es decir, hay un promedio diferente. Hay un que } Hay más variación al comparar los grupos que la variación dentro de los grupos .
Ejercicios
Aquí se pueden hacer los ejercicios 1 y 2 de Contento, página 372
Ejemplo
Supongamos que para un proceso tenemos los siguientes valores y sus respectivos promedios.
Los representamos en la siguiente gráfica.

Aquí podemos ver que los poromedios tienden a estar cerca entre ellos.
Ahora, . Entonces y y . Fijate que no se cumple que >
Ahora si la tabla fuese diferente, por ejemplo la siguiente:
Aquí los valores azules están alejados de los verdes y rojos, como se puede ver en la gráfica:

Calculamos los valores, encontrando
,
Vemos que se cumple que >
Prueba de Hipótesis para ANOVA
Los cuadrados medios y representan variables grupos y de los grupos. Su división es una variable aleatoria que se distribuye como una función con y grados de libertad.
-
-
Si la es verdadera (no hay efecto del tratamiento, ), CMTr (y por lo tanto ) es pequeño.
-
Si es alto hay evidencia de que es falsa. ( tratamientos mayor que ). Por lo menos un promedio es diferente y se rechaza
-
La probabilidad de que aleatoriamente, sólo por coincidencia, ocurra éste evento se calcula como: . A medida que este valor se hace más pequeño es cada vez menos probable.
-
La prueba indica “nivel de significancia” , que es una medida de qué tan improbable es el resultado. Usualmente se trabaja con un nivel de significancia del 5%, es decri 0.05. Cuando la probabilidad es menor a éste valor se concluye que no se debió al azar.
Ejemplo (Contento 2019, pg. 362)
Niveles de atención (minutos) de lectura matutina, en tres grupos
| Sin Desayuno | Desayuno ligero | Desayuno completo |
|---|---|---|
| 8 | 14 | 10 |
| 7 | 16 | 12 |
| 9 | 12 | 16 |
| 13 | 17 | 15 |
| 10 | 11 | 12 |
| \ | Sin Desayuno | Desayuno ligero | Desayuno completo |
|---|---|---|---|
| Totales | 47 | 70 | 65 |
Para trabajarlo en Python:
- Se cargan las librerías
import pandas as pd
import statsmodels.api as sm
import seaborn as sns
import matplotlib.pyplot as plt
import scipy.stats as stats
plt.ion()
from statsmodels.formula.api import ols
- Se ingresan los datos
datos = pd.DataFrame({'atencion':[8,7,9,13,10,14,16,12,17,11,10,12,16,15,12],'tipo_desayuno':['sin','sin','sin','sin','sin','ligero','ligero','ligero','ligero','ligero','completo','completo','completo','completo','completo']})
- Se crea un modelo explicativo, en este caso lineal:
lm = ols('atencion ~ C(tipo_desayuno)',data=datos).fit()
- Se construye el ajuste por ANOVA:
tabla_anova = sm.stats.anova_lm(lm,typ=2)
tabla_anova
El resultado es el siguiente:
| . | sum_sq | df | F | PR(>F) |
|---|---|---|---|---|
| C(tipo_desayuno) | 58.533333 | 2.0 | 4.932584 | 0.027326 |
| Residual | 71.200000 | 12.0 | NaN | NaN |
La tabla indica los valores de la suma de cuadrados, los grados de libertad de grupos y datos, el valor de y la probabilidad de encontrar ese valor por azar, . Como este valor es más pequeño al 5%, pero más grande al 1%, se concluye el resultado es significativo a un nivel de 5%.
Ejemplo 2, Khan Academy:
Se puede ver en el siguiente video: https://youtu.be/46CVRPdlKHc?si=0xxT_TOcSO5rWHV0
Condiciones para ANOVA
Para que se pueda aplicar el método del análisis de varianza, y sus resultados tengan sentido, se tinen que cumplir una serie de condiciones.
-
Normalidad de los residuales: la distribución de los errores experimentales debe ser una distribución gaussiana.
-
Homogeneidad de la varianza (homocedasticidad): las varianzas de las variables dependientes deben ser aproximadamente similares entre los grupos de tratamiento.
-
Independencia: no hay relación entre las observaciones de diferentes grupos, son independientes entre ellos
Y relacionado con estos tenemos también la continuidad de la variable dependiente, ya que cuando esta variable no lo és se invalida la condicion de normalidad y homogeneidad de la varianza.
Pruebas para las condiciones
Se investigan con estadísticos de prueba (Shapiro, Levene, entre otros) o gráficamente (gráficos de residuos QQ o histogramas)
Normalidad
Shapiro
Usando el test de shapiro:
stats.shapiro(lm.resid)
El resultado son dos números, la estadística de prueba y el nivel de
significacncia, . La hipótesis nula es que si se distribuyen
de manera normal. En este caso se obtiene el siguiente texto:
ShapiroResult(statistic=np.float64(0.9272863300806745), pvalue=np.float64(0.24845535561613769)). Es decir, el valor del
estadístico de prueba es 0.9272863300806745, y la significancia es
0.24845535561613769. Cómo éste valor no es menor a 0.05, no tenemos
evidencia contra la hipótesis nula; es decir que aceptamos que se
cumple la condición de normalidad de los rediduos.
Gráficamente
fig = plt.figure(figsize= (10, 10))
ax = fig.add_subplot(111)
normality_plot, stat = stats.probplot(lm.resid, plot= plt, rvalue= True)
ax.set_title("Probability plot of model residual's", fontsize= 20)
ax.set
Se obtiene la siguiente gráfica:
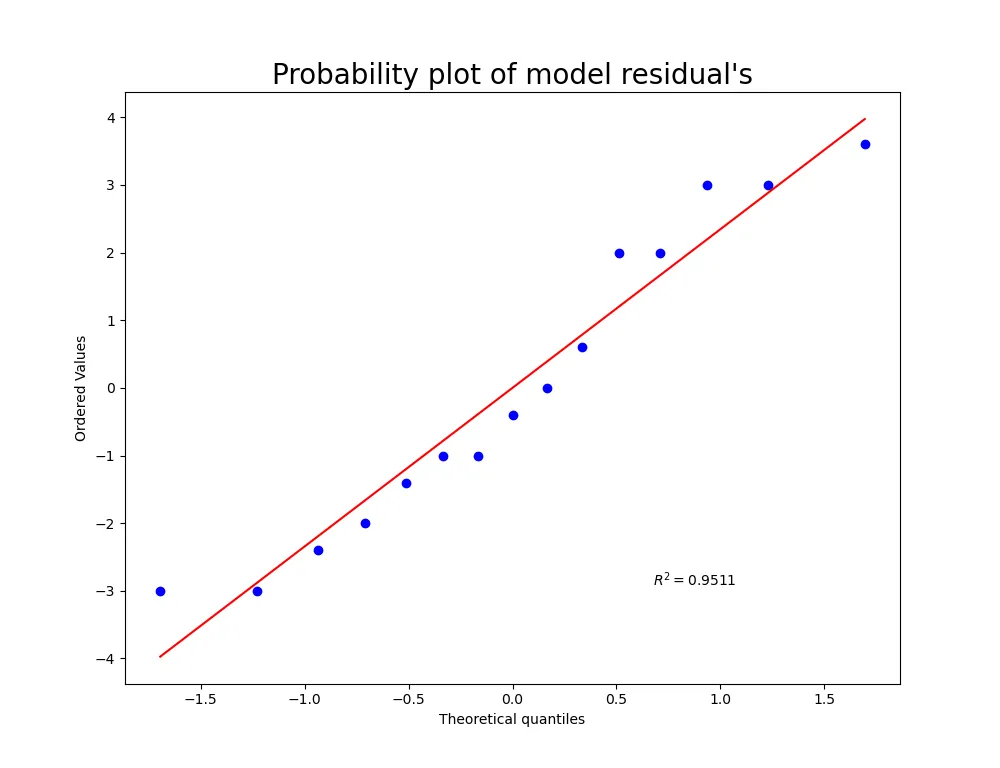
Homogeneidad de la varianza
Primero construimos una tabla de los datos divididos por categorías.
data = [datos['atencion'][datos['tipo_desayuno'] == 'sin'],
datos['atencion'][datos['tipo_desayuno'] == 'ligero'],
datos['atencion'][datos['tipo_desayuno'] == 'completo']]
A continuación se genera la gráfica.
fig = plt.figure(figsize= (10, 10))
ax = fig.add_subplot(111)
ax.set_title("Tiempos de atención", fontsize= 20)
ax.set
ax.boxplot(data,
labels= ['sin', 'ligero', 'completo'],
showmeans= True)
plt.xlabel("Desayuno")
plt.ylabel("Atención")
El resultado es la siguiente gráfica:
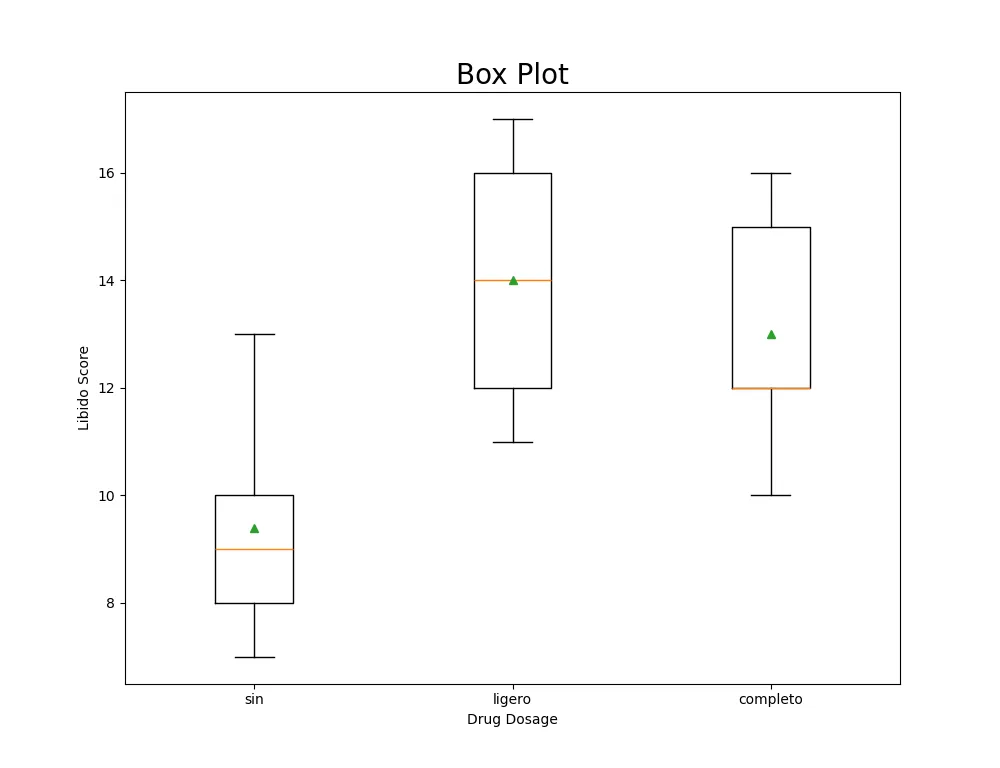
En el cuadrado verde está el promedio . La línea naranja es la mediana.
¿usted diría que la distribución es simétrica?