Google Colab trae instalado un asistente LLM de programación llamado
Gemini. Tiene tres dos interfaces:
-
Una opción en la célda de código, que se activa haciendo click en la palabra
generate
-
Una ventana tipo chat que se abre haciendo click a la derecha en la palabra
Gemini
Celda de código
Se hace click en la palabra generate, lo que hace que el ícono a la
izquierda que representa la celda cambie a ser un lápiz con una
estrella. Esto denota que la celda ahora es un prompt o instrucción
para que el LLM genere código.
Chat
Al hacer click en Gemini sale una ventana de chat que nos permite
dar instrucciones al LLM.
Vamos a intentar usarlo para cargar el archivo que tenemos. Pero primero:
Cuidados ❗
-
El sistema está en “la nube”, luego los datos que suba están siendo compartidos con un tercero. Además al aceptarlo estamos aceptando que se usen los datos y el código como entrenamiento. Esto implica que su uso es ilegal en algunos casos. Por ejemplo cuando se trabaja con bases de datos que tienen información privada de personas en Colombia,
-
Es costoso computacionalmente, (así Google no nos transfiera esos costos directamente (todavía)), tiene gastos ambientales grandes.
Codificaciones
Según wikipedia, “La codificación de caracteres es el método que permite convertir un carácter de un lenguaje natural (como el de un alfabeto o silabario) en un símbolo de otro sistema de representación, como un número o una secuencia de pulsos electrónicos en un sistema electrónico aplicando normas o reglas de codificación.”
En computación son necesarios porque los datos se guardan justamente en archivos electrónicos en los que existen secuencias de números y letras.
En la práctica, esto implica que para “abrir un archivo” necesitemos saber cuál es el sistema de codificación con el que fue grabado. Este proceso no es automágico, porque a una representación electrónica dada le pueden corresponder diferentes caracteres. Si usted se encuentra con un archivo y no sabe cual es la codificación, se recomienda:
-
Revisar la documentación del archivo o de la fuente del archivo, para saber cómo se codificó.
-
Revisar el archivo con diferentes codificaciones y revisar si produce resultados inteligibles.
Ejemplo, Datos del DANE
En los datos del DANE que hemos usado anteriormente hemos tenido que usar diferentes codificaciones, por ejemplo:
df = pd.read_csv("Nacimientos_1998_25-5-2024.txt",encoding="ISO-8859-1",sep="\t")
En este caso la palabra encoding indica la codificación.
Solicitar a Google Gemini cargar un archivo secuencialmente con diferentes codificaciones
Supongamos que tenemos el archivo nac2021.csv. Lo intentamos leer
con el siguiente código:
# prompt: read a dataframe called nac2021.csv
# check the encoding coding
import pandas as pd
df = pd.read_csv('nac2021.csv')
Genera el siguiente error (al final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xcc in position 161614: invalid continuation byte
Esto indica que si se tomase la codificación por defecto (utf-8)
habría un texto que no se puede traducir, luego probablemente se
puede asumir que hay un error de codificación.
Intentamos que Google Gemini intente cargar el archivo con diferentes codificaciones.
Intentamos que Gemini genere un código que cargue el archivo, así falle. Usamos la instrucción:
intente generar un dataframe del archivo nac2021.csv, pero revisando varias codificaciones
El código generado es el siguiente:
import pandas as pd
encodings = ['latin-1', 'utf-8', 'iso-8859-1', 'cp1252']
for encoding in encodings:
try:
df = pd.read_csv('nac2021.csv', encoding=encoding)
print(f"Successfully read with encoding: {encoding}")
# You can add further processing of the dataframe here if successful
break # Exit the loop if successful
except UnicodeDecodeError:
print(f"Failed to read with encoding: {encoding}")
continue # Try the next encoding
else:
print("Failed to read the file with all tested encodings.")
- ¿cómo podemos determinar si el código hace lo que dice que hace?
- ¿cómo podríamos usar éste código fuera de línea? (por ejemplo para trabajar con dbases que tengan datos privados)
Try/except
(La bibliografía de ésta sección es el libro: Doing Computational Social Science A Practical Introduction, de McLevey pg. 67)
Existen dos tipos de problemas con el código en Python:
-
Errores: el comando no está bien escrito sintácticamente. Por ejemplo:
pd.read_csv("nac2021.csv)Aquí hay un error de sintáxis, falta cerrar las comillas.
Pythonlo identifia comoSyntaxError, y nos identifica con una flechita dónde está el error: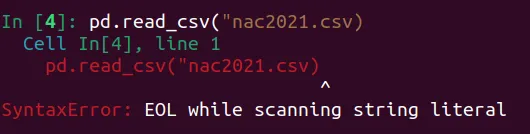
-
Excepciones: el comando si está bien escrito sintácticamente, e igual no corre
- El código se interrumpe
- Python muestra un seguimiento de la excepción (
Traceback)
Ejemplo, el siguiente comando no tiene errores de sintaxis:
pd.read_csv("nac2021.csv")Sin embargo
Pythonindica que hay un error de codificaciónUnicodeDecodeError: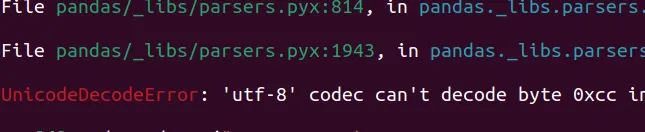
En este caso hay un
Traceback, que se caracteriza por una serie de referencias a líneas de código. Lo importante para nosotros es esa última información, elUnicodeDecodeError.
Ejemplo (❌💫 ):
Explique, ¿que hace el siguiente código?
numero = "siete"
if numero<3:
print("es")
else:
print("no es")
Intentemos solucionarlo con un try-except
Podríamos intentar saltarnos la excepción:
numero = "siete"
try:
if numero<3:
print("es")
else:
print("no es")
except:
print("no cancionó")
Python intenta reproducir el bloque marcado debajo de try. Si no
puede, no falla, ejecuta el bloque debajo de except.
Críticas al try-except
-
Hace más difícil de leer el código
-
Se basa en ‘capturar una excepción’. Pero puede ser que la excepción que termine ocurriendo no sea la que planeabamos que pasara. Por ejemplo, pensabamos que la excepción sucede cuando se compara texto con números, pero en realidad ocurre un error de codificación. Como el código no falla (por el
try-except), es mucho más difícil hallar el error.
Enlaces
-
Google Gemini: https://www.youtube.com/watch?v=V7RXyqFUR98