Table of Contents
Open Table of Contents
- Bases de Datos
- Introducción a las bases de datos y su importancia en la gestión pública de datos.
- Manipulación y estructura de bases de datos para creación, cargue, limpieza y transformación. Tipos de archivos, preparación de datos.
- Codificación
- Python y Pandas
- Consultas de bases de datos usando librerías. Filtros (por index, variables y casos) y ordenación
- Operaciones con bases de datos: fusionar y unir, aplicar operaciones
- Transformación y reporte de la información de los conjuntos de datos
- Bibliografía
Bases de Datos
Introducción a las bases de datos y su importancia en la gestión pública de datos.
La concepción misma del Estado moderno involucra una serie de responsabilidades por parte de los funcionarios que representan las diferentes instituciones. En el terreno administrativo esto lleva al surgimiento de la burocracia, entendida como el entramado de personas y reglas que llevan a cabo las funciones administrativas que la sociedad define que son responsabilidad del Estado.
Desde su inicio, el actuar del Estado ha requerido el registro y almacenamiento de diferentes tipos de información relativa a las personas primero, y luego a empresas. En la época contemporánea esta información se maneja de manera electrónica; lo que lleva a requerir maneras organizadas de registrar esta información. La respuesta técnica desde la ingeniería consiste en la organización de la información en forma de bases de datos.
En el contexto aplicado a las ciencias sociales, las bases de datos son archivos electrónicos que están construidos de manera estructurada para organizar diferentes tipos de información. Su diseño permite crear procedimientos sencillos y reproducibles para manejar la información. Esto permite que sean parte de procedimientos orientados al manejo responsable del conocimiento, ya sea de tipo científico o técnico.
En el contexto Colombiano, diferentes estamentos estatales tienen la responsabilidad de construir, proteger y garantizar la integridad de diferentes conjuntos de datos. Esta información hace parte del acervo intelectual de la Nación, por lo que las reglas y procedimientos de manejo cumplen protocolos estrictos, que permiten garantizar su utilidad.
Por otro lado, aunque estos conjuntos de datos son de propiedad de la Nación en su conjunto, hay diferentes niveles de acceso; que van desde el carácter pública hasta el reservado.
Manipulación y estructura de bases de datos para creación, cargue, limpieza y transformación. Tipos de archivos, preparación de datos.
Codificación
Corresponde al proceso de dar instrucciones a las computadoras para automatizar las operaciones sobre la información. Se hace mediante archivos de texto en los que están escritas las instrucciones, lo que lo diferencia del uso de programas orientados a las operaciones visuales; como pueden ser las hojas de cálculo o los procesadores de palabras. En esta sección haremos una corta introducción, refiriéndole a otros textos en los que puede profundizar en la materia.
Tipos de interfaces
La interacción con la computadora se puede resumir en dos formas principales, llamadas también interfaces. Aunque algunos sistemas son mixtos, permiten incluir ambos tipos de estrategias.
-
Lo que haces es lo que ves: Las modificaciones en la información, ya sea texto o datos, se ven reflejadas directamente en la pantalla. Se basa fuertemente en el uso de íconos, ya sea con el Mouse o con pantallas táctiles. Son útiles para interacciones esporádicas, ya que las gráficas ayudan que lo quien las usa pueda recordar cómo se interactúa; no requieren aprender o recordar. No permiten reproducibilidad y son engorrosas para tareas repetitivas, además de son poco eficientes para conjuntos de datos grandes. Ejemplos:
-
Procesadores de texto, como Google Docs o Word
-
Hojas de cálculo, como Excel o Google Sheets
-
-
Codificación: Separan las instrucciones de los productos en archivos diferentes. Se basan en un lenguaje, escrito en texto, en el que se ingresan las instrucciones, que actúan sobre la información. Requieren comprender una sintaxis, lo que hace menos útiles para interacciones esporádicas. Son bastante eficientes, luego para usuarios intermedios o avanzados pueden generar ahorros en tiempo. Permiten reproducibilidad, lo que ayuda en la colaboración y la verificación de los procesos. Se pueden apoyar en sistemas de control de versiones, que permiten registrar cambios en procedimientos y procesos. Ejemplos:
-
Python+Pandas para el trabajo de bases de datos (eje principal de éste curso)
-
Archivos Do-File de STATA para el trabajo de bases de datos
-
Markdown o LaTeX para documentos de texto
-
Etapas de codificación
-
Preparación del Entorno: Es el proceso de iniciar el entorno de ejecución, y cargar las librerías que se van a usar.
-
Ingreso de información: Asignaciones, lectura de archivos. Se llaman también “asignaciones”. En codificación tendrás un nombre de variable y un valor. El nombre de la variable es como un contenedor y el valor es lo que tiene adentro. Puedes reutilizar el contenedor para luego poner otra cosa allí.
-
Procesamiento de información: Operaciones, Funciones, Condicionales, Flujo y control. Se pueden hacer con símbolos (operadores) o con funciones. Es lo que queremos que el PC se encargue de trabajar. Aunque parezca magia, en el fondo son sólo operaciones matemáticas que el computador hace para llegar a la respuesta. Mientras tanto nosotros podemos dedicarnos a otras actividades más humanas.
-
Reporte de los resultados: Función
print, escritura de archivos. Una vez que el PC ha machacado los datos, podemos preguntarle los resultados. -
Validación. Pensar, analizar: Aquí nos toca pensar de nuevo. ¿eso que dijo el PC tiene sentido? o habremos cometido un error -ya sea tipográfico o más profundo.
Entornos de ejecución
Python se puede ejecutar de manera local, en su computadora, sin uso de internet. O también haciendo uso de sistemas de computación en línea, que dependen del internet, y para los que su información está compartida con un tercero.
Para usarlo de forma local recomendamos instalar la versión jupyter notebook.
Para usarlo a través de internet, se puede hacer uso de una cuenta de google y usar google colab.
Iniciar Python en Google Colab
- Acceda a una cuenta de Google
- Vaya a https://colab.research.google.com/?hl=es
- Haga click en Archivo-> Nuevo Cuaderno
Iniciar Python en Jupyter Notebook
Instalar Jupyter Notebook en Windows: instalador gráfico
El procedimiento en inglés está en la siguiente página: https://www.anaconda.com/docs/getting-started/anaconda/install/windows-gui-install
El procedimiento es el siguiente. Primero, se debe ir a la página https://anaconda.com/download. Allí se hace click en “Get Started”
A continuación debe registrarse como usuario, se puede hacer con el correo electrónico o usando cuenta de Google
A continuación se puede descargar la versión más actual, e instalarla.
Al momento de escrita de ésta página, la versión más actualizada se puede conseguir en el enlace: https://repo.anaconda.com/archive/Anaconda3-2025.12-2-Windows-x86_64.exe.
Después de haber instalado Anaconda, ya puede borrar el archivo de instalación (el que tiene un nombre como Anaconda3-2025.06-0-Windows-x86_64.exe o similar), porque no lo necesitamos más.
Se abre el programa “Anaconda Navigator” en el menú de programas de Windows.
Y allí se busca “Jupyter Notebook”. OJO, hay otros diferentes que no usaremos, como Jupyter LAB.
En este video de Youtube explican: https://www.youtube.com/watch?v=pGuBv_tm2CY
osX
El procedimiento en Inglés está en la siguiente página: https://www.anaconda.com/docs/getting-started/anaconda/install/mac-gui-install
Según: https://phoenixnap.com/kb/install-jupyter-notebook
-
Mediante el comando brew
En una terminal:
brew install jupyterlab
Luego se corre, desde la terminal, con:
jupyter notebook
Y listo!
-
Mediante la línea de comandos
Como otra opción, se puede hacer de ésta forma. Primero, se debe crear un ambiente
Usando, desde la terminal, por ejemplo:
python3 -m venv jupyter
Activar python:
source jupyter/bin/activate
Esto activa el ambiente virtual. Luego se puede instalar jupyter:
pip install jupyter
-
Desde Anaconda
Se pueden seguir las instrucciones que están en la versión Windows y bajar el paquete. Al momento de escribir esto, el enlace es https://repo.anaconda.com/archive/Anaconda3-2025.12-2-MacOSX-arm64.pkg
Arch Linux
En ARCH-Linux y similares (Manjaro, CachyOS, etc), instalar el paquete jupyter-notebook. sudo pacman -S jupyter-notebook. Listo.
Ubuntu Linux
En Ubuntu-Linux es un poco más largo. Primero se debe actualizar Ubuntu con
sudo apt update && sudo apt upgrade -y
Luego instalar python3:
sudo install python3-pip python3-venv -y
Luego crear el ambiente virtual:
python3 -m venv ~/jupyter-env
Luego se activa:
python3 -m venv ~/jupyter-env
source ~/jupyter-env/bin/activate
Luego se actualiza pip:
python -m pip install --upgrade pip
Y se instala
python -m pip install notebook
Se ejecuta como
jupyter notebook
Cómo ejecutar el código (tanto Colab como Jupyter)
- Las instrucciones se escriben en la Celda y se ejecutan con el botón triangular.
- Cada celda puede tener varias instrucciones
- Un cuaderno se puede guardar para usarlo en el futuro
- Importante, indentación
Tipos de instrucciones
Tanto en hojas de cálculo como en sistemas de codificación, existen los siguientes tipos de instrucciones al interactuar con la computadora:
-
Operaciones: La aritmética y estadística descriptiva. Como ejemplo: sumar dos variables. En hojas de cálculo se operan con el símbolo igual en la casilla. En sistemas de codificación se puede escribir de manera análoga a cómo se haría con una calculadora. Por ejemplo:
3+5123*27 -
Asignaciones: Registrar un valor, que será usado en el futuro. En hojas de cálculo corresponde a escribir un valor en una casilla. En sistemas de codificación se asigna un valor a la variable, luego el igual, y luego su valor. Por ejemplo:
a = 8ciudad = "Guadalajara"lista = [1,2,3,4]df1 = pd.DataFrame({'nombres':['Luis','Adriana','Vi'], 'apellidos':['Gómez','Ramírez','Castro']})Un error común es asumir que las asignaciones deben mostrar algo a pantalla. Quienes están aprendiendo suelen decir, “ejecuté la instrucción, pero no pasó nada”. Olvidan que lo que pidieron al computador es asignar un valor a un nombre de variable, luego no se espera que se imprima nada a pantalla. Dicho de otra forma, asignar es diferente a imprimir.
-
Funciones: Procedimientos predefinidos sobre los datos. Tanto en las hojas de cálculo como en codificación son caracterizados por un nombre de la función, seguido por paréntesis. Entre los paréntesis van tanto los argumentos de la función como los parámetros. Ejemplos:
sum(lista) pd.read_csv("Nacimientos_1998.csv","sep=";") print(" el valor de la variable a es ",a)Hay amplia flexibilidad en las funciones. Pueden servir para cargar datos a memoria, para hacer cálculos, para generar gráficas, etc.
-
Condicionales: Asignan valores dependiendo del valor de otras variables. Ejemplos:
if a>3: print(" el valor de la variable a es mayor a 3") -
Flujo y Control: Permiten incorporar estrategias o algoritmos. No los vamos a ver en este curso. Incluyen estructuras de repetición, como los for.
Ayuda: ?
Pythontiene un sistema de ayuda incorporado, que entrega información sobre diferentes instrucciones. Se accede añadiendo la interrogación después de la instrucción. Por ejemplo:
sum?
Devuelve lo siguiente:
Signature: sum(iterable, /, start=0)
Docstring:
Return the sum of a 'start' value (default: 0) plus an iterable of numbers
When the iterable is empty, return the start value.
This function is intended specifically for use with numeric values and may
reject non-numeric types.
Type: builtin_function_or_method
Después de Signature se indica cuál es la forma de llamar la función. En este este caso indica que el primer argumento es un iterable, lo que quiere decir listas o vectores. Después de Docstringnos indica que hace la función. En este caso dice que devuelve la suma de un valor inicial, llamado start y que por defecto vale 0, al contenido del iterable.
Es decir, que si indicamos:
lista0 = [1,2,3]
sum(lista0)
Esperamos que la respuesta sea 6. Pero si decimos:
lista0 = [1,2,3]
sum(lista0,-5)
Esperamos que la respuesta sea 1.
Auto completar instrucciones, TAB 
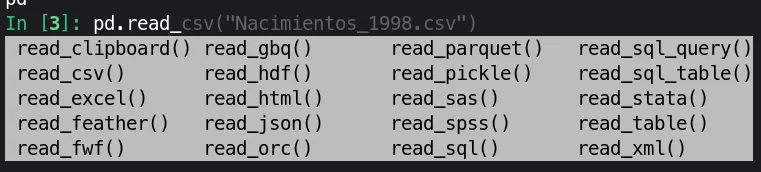
Python permite auto completar algunas instrucciones, principalmente las funciones. Por ejemplo, si ya se iniciado el entorno como indicamos en la sección anterior, el sistema tendrá cargadas en su memoria los nombres de todas las funciones de numpy. Entonces, si usted no quiere buscar en este documento o en el internet el nombre de la función para ingresar datos, puede:
-
Teclear el principio del nombre de la función, es decir:
np.read_
-
Usar la tecla de tabulación (TAB
), para que Pythonindique cuáles son las posibles funciones de la librería numpy, cuyo nombre comienza porread_.
Programación orientada a objetos.1
Objetos
Los objetos son estructuras de datos, que tienen características y métodos. Son parámetros (valores) o funciones. En la práctica, guardan información (su tamaño, qué tipo de dato es) y funciones (operaciones).
Ejemplo: Texto
El primer tipo de objeto que vamos a ver es el texto. Como ejemplo, definamos una cadena de texto, que se llama ciudad y que tiene el valor Guadalajara:
ciudad = 'Guadalajara'
En este caso se ingresa el texto entre comillas, para hacer diferencia entre textos y nombres de variables. Ahora que la cadena existe, se puede hacer uso de métodos (funciones) que la alteran. Por ejemplo, podemos averiguar si la cadena es de texto, si tiene números, o generar una nueva cadena con el texto en mayúsculas:
ciudad.isalpha()
ciudad.isdigit()
ciudad.upper()
Para averiguar los nombres de todas las posibles funciones que se le pueden aplicar a la variable ciudaddebido a que es una cadena de texto, se puede teclear: ciudad., seguido de la tecla TAB ![]() .
.
Listas
El segundo tipo de objetos que vamos a ver son las Listas. Son colecciones o contendedores alterables, en el sentido de que se pueden añadir, quitar, o modificar los elementos de una lista. Son iterables en el sentido de que se puede recorrer el contenedor. Pueden ser heterogéneas, en el sentido de que pueden contener números, texto u otro tipo de objetos.
Para crearlas “por extensión”, se usan los corchetes: [] o el comando list(). Sus elementos se pueden acceder con [i], i empieza en 0.
Ejemplo
Generemos una lista heterogénea, de números y texto.
numerosEnLista = [1,2,3,3,4,'5']
Podemos identificar todas las funciones que se pueden aplicar a la lista haciendo uso del tabulador. Tecleamos numerosEnLista. seguido por la tecla TAB.

Si queremos averiguar qué hace la función cont podemos escribir:
numerosEnLista.count?
A lo que el sistema devuelve:
Signature: numerosEnLista.count(value, /)
Docstring: Return number of occurrences of value.
Type: builtin_function_or_method
De aquí entendemos que para llamar la función teclearíamos la función y entre paréntesis le daríamos un valor. Y la función devolvería el número de ocurrencias de ese valor. Por ejemplo, aquí podríamos decir:
numerosEnLista.count(3)
Lo que devuelve el número 2, indicando que el valor 3 está 2 veces en la lista numerosEnLista.
La clase lista no tiene una función que imprima su contenido. Para eso usamos una función general de Python, la función print:
print(numerosEnLista)
Para acceder al primer elemento de la lista usamos el índice i=0. Lo podemos cambiar de la siguiente manera:
numerosEnLista[0]='cero'
Para corroborar el cambio, imprimimos:
print(numerosEnLista)
Ejemplo: Lista
Nombres = ['Carlos','Antonia','luisa']
Nombres.sort()
Nombres.append('Jo')
Ejercicio
- Defina una lista cuyos 4 elementos sean el número 1, llámela
lista0. - Imprima
lista0a pantalla - Modifique
lista0, para que ahora el segundo elemento de la lista sea el número 2. - Imprima
lista0a pantalla
Añadir elementos a una lista
Cuando la lista ya existe, se puede añadir elementos con la función
append:
lista0 = ['uno','dos','tres']
print(lista0)
lista0.append('4')
print(lista0)
- Define una lista, la llama
lista0 - Imprime la lista
- Para modificar la lista, le añade el texto 4.
- Vuelve a imprimir la lista
Ejercicio
Modifique la lista para añadir la palabra ‘chigüiro’. Imprima la lista.
Operaciones entre variables: Comparaciones
Al operar sobre datos, podemos requerir comparar los valores de las variables. En Python esto se hace con unos símbolos específicos, llamados operadores. Se resumen en la siguiente tabla:
| Operador | Significado |
|---|---|
== | Igualdad |
!= | No es igual |
> | Mayor |
>= | Mayor o igual |
< | Menor |
<= | Menor o Igual |
in | ¿está en? |
Comparar cadenas
Comparemos las siguientes cadenas. Primero definimos una variable llamada ciudad, que tiene el valor Guadalajara:
ciudad = 'Guadalajara'
Ahora, si quisiéramos saber si el valor de la variable ciudad es México, haríamos uso el operador de igualdad. Por ejemplo:
'México' == ciudad
El sistema devuelve como resultado de la operación el valor False, indicando que la variable ciudad no es igual a la cadena México. Qué espera que pasa si ejecuta las siguientes instrucciones? Piense primero y luego proceda a corroborar.
'Gua' == ciudad
'Guadalajara' == ciudad
'Gua' in ciudad
En el último caso estamos haciendo uso del operador in que indica si las letras hacen parte o no de la cadena.
Comparar variables numéricas
De manera similar, podemos comparar variables numéricas. Comenzamos por definir una variable llamada unNumero, que tiene el valor 3:
unNumero = 3
Que espera que pase al ejecutar cada una de las siguientes instrucciones? Piense, y luego corrobore.
unNumero < 2
unNumero >= 3
unNumero != 983
En este último caso estamos haciendo uso del operador !=, que significa “es diferente”.
¿el valor está en la lista?
El operador in también puede usarse para averiguar si una variable hace parte de una lista. Qué espera que pase al ejecutar las siguientes instrucciones? Corrobore.
Nombres = ['Carlos','Antonia','luisa','jo']
'Antonia' in Nombres
'car' in Nombres
Python y Pandas
Python es software libre. Es un lenguaje de programación flexible de código abierto; cuyo desarrollo está organizado por la Python Software Foundation. Es decir, no hay una empresa que sea dueña del software (es ‘de todos’). Esto lleva a que haya diferentes implementaciones.
Etapas de Codificación en Python: Preparación del entorno
Las librerías son conjuntos de software que amplían las funciones básicas de Python. Las que usaremos son las siguientes:
- pandas: Permite el manejo de bases de datos.
- scipy.sats Incluye las funciones estadísticas
- matplotlib.pyplot Incluye instrucciones para graficar los datos
- numpy Permite hacer cálculos numéricos avanzados
- random Tiene funciones para números aleatorios.
Al inicializar se les asigna un apodo, o alias, para diferenciar funciones provenientes de diferentes librerías y para agilizar su uso. Las ingresamos así:
import matplotlib.pyplot as plt
import scipy.stats as st
import pandas as pd
import numpy as np
import random as ran
De aquí en adelante se pueden usar las funciones de pandas usando el alias pd, seguido del punto.
Etapas de Codificación en Python: Ingreso de información
En los procesos de investigación, administración o gobierno en el campo de lo público, una parte importante del trabajo pasa por construir los conjuntos de datos requeridos para las funciones precisas de cada caso. No vamos a entrar a explicar este proceso, ya que se fundamenta en conocimientos disciplinares de cada una de las áreas de aplicación de la ciencia de datos a las ciencias sociales.
Esta información será registrada en diferentes conjuntos de datos. Operativamente estos son archivos de computadora de diferentes tipos, como pueden ser archivos de hoja de cálculo de Excel, archivos separados por comas, archivos de base de datos de STATA, etc. Cuidado! usualmente para determinar el tipo de archivo nos guiamos por el ícono que muestra, pero realmente este sólo indica qué programa en el pasado ha indicado que puede abrir los archivos. De manera que un ícono de Excel, por ejemplo, puede aparecer asociado a un archivo separado por comas. Para identificar el tipo de archivo se debe usar la opción propiedades del sistema operativo, y allí revisar el nombre completo del archivo. Por medio de las extensiones se determina el tipo.
Pandas tiene una familia de instrucciones que permiten ingresar la información proveniente de los diferentes tipos de archivos. Todas comienzan por la palabra read. Ejemplos:
| extensión | tipo de archivo | Función de Pandas |
|---|---|---|
| .csv | archivo separado por comas | read_csv |
| .xlsx | hoja de cálculo de excel | read_excel |
| .dta | archivo de datos de STATA | read_stata |
Auto completar nombres de archivo
Python tiene conocimiento de qué archivos están en la carpeta que intentamos leer, y puede auto completar el nombre del archivo. Por ejemplo, si en la carpeta hay un archivo que se llama README y escribimos np.read_csv("R y a continuación presionamos el tabulador, el computador nos auto completará con el nombre de archivo README. Esto es útil para no cometer errores al teclear nombres de archivo que están en la carpeta.
Errores comunes: Tipos de Codificación
La codificación es la relación entre los caracteres que se ven en pantalla y su representación en binario en la memoria del computador. Existen diferentes tipos de codificación, porque inicialmente no se incluían caracteres que no están en el idioma inglés. Luego con el tiempo se ha tenido que modificar. Actualmente se busca ir hacia una única codificación, llamada UTF-8, que es la codificación por defecto. Pero los archivos todavía pueden tener otros tipos de codificación.
Al intentar leer un archivo en pandas sin tener en cuenta la codificación, o usando la codificación errada, surge un error del siguiente tipo:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xd3 in position 138118: ordinal not in range(128)
Este texto aparece al final de una cadena de error más larga. Lo que está indicando es que existe una parte del texto en la que hay un símbolo en bytes, que no se puede decodificar bajo el formato ascii.
Para solucionar este problema se cambia el tipo de codificación. Las opciones más comunes son:
| codificación | Opción para el comando read_csv en Pandas |
|---|---|
| ISO-8859-1 | encoding=‘ISO-8859-1’ |
| UTF-8 | encoding = ‘utf-8’ |
Errores comunes: Separador de Campos
Los archivos separados por comas están escritos en texto plano, y los campos se separan por comas. Si se imprime sus contenidos a pantalla se van a ver, por ejemplo, así:
COD_DPO, COD_MPO
26,6
27,73
76,606
En este caso tenemos una base de datos que tiene dos variables: COD_DPO y COD_MPO, y tres registros. El primero tiene COD_DPO en 26 y COD_MPO en 6, y así sucesivamente. Si intentamos leer esto con Pandas, la computadora debe saber que los campos se separan con comas. Porque podrían separarse con otra cosa, por ejemplo con punto y coma:
COD_DPO;COD_MPO
26;6
27;73
76;606
O tabulador, etc.
Cuando se intenta cargar una base de datos con el separador equivocado, al final del error sale un texto similar al siguiente:
ParserError: Error tokenizing data. C error: Expected 1 fields in line 2764, saw 3
Lo que dice es que en la línea 2764 encontró un registro con 3 variables, pero esperaba un registro con una variable. Seguramente el archivo tiene aún más de 3 variables, pero como el sistema no sabía cuál es el separador, lo tomaba como si fuera una única variable. Es decir, si el intenta leer
COD_DPO,COD_MPO,AREANAC,SEXO,APGAR1
separándolo por punto y comas, no vería si no una única variable (y no cinco como debería ser el caso). Para solucionar este problema se usa la opción sep:
| separador | Opción para el comando read_csv en Pandas |
|---|---|
| ; | sep=”;“ |
| , | sep=”,“ |
| tabulador | sep=“\t” |
Etapas de Codificación en Python: Procesamiento de información
El proceso de procesamiento de información involucra varias sub-etapas. La primera consiste en la visualización de la información.
Visualización de Histogramas
Supongamos que tenemos los siguientes datos para tardanzas en una empresa en 57 días 2
tardanzas = [68, 63, 42, 27, 30, 36, 28, 32, 79, 27, 22, 23, 24, 25,
44, 65, 43, 25, 74, 51, 36, 42, 28, 31, 28, 25, 45, 12,
57, 51, 12, 32, 49, 38, 42, 27, 31, 50, 38, 21, 16, 24,
69, 47, 23, 22, 43, 27, 49, 28, 23, 19, 46, 30, 43, 49, 12]
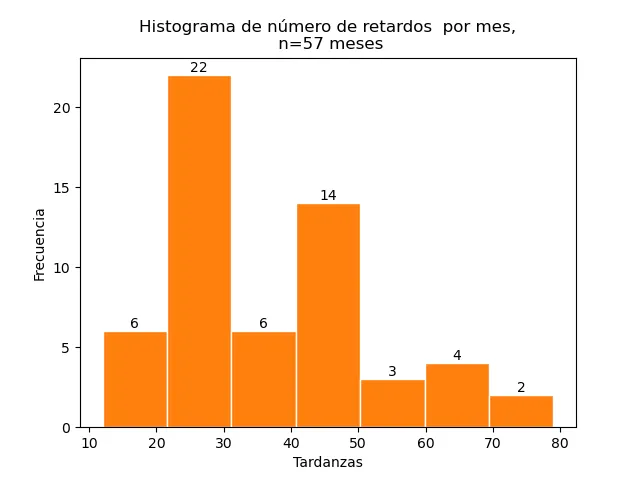
Queremos hacer un histograma de 7 divisiones3. Para incluir el valor del número de repeticiones en cada clase del histograma hay que incluir tres variables a la izquierda del comando plt.hist, una para el conteo, otra para los bordes y otra para las barras. Luego se usa el comando plt.bar_label con argumento barras.
cuentas,bordes,barras = plt.hist(tardanzas,bins=7, edgecolor='w')
plt.bar_label(barras)
plt.title("Histograma de número de retardos por mes, n=57 meses")
plt.xlabel("Tardanzas")
plt.ylabel("Frecuencia")
Estructuras de bases de datos en pandas: el DataFrame
El resultado de utilizar una función pd.read_csv (u otras similares), es cargar los datos del archivo de texto a Pandas. Esto genera un objeto en la memoria de la computadora. El tipo de objeto es DataFrame.
Como ejemplo, descarguemos los datos de la página del DANE para Nacimientos en 1998 como un DataFrame, y revisemos sus características. Vamos a la página: https://microdatos.dane.gov.co/index.php/catalog/366/get-microdata Haga click en Nacimientos 1998 y luego en Descargar.
Esto baja un archivo zip:
Al extraerlo hay dos archivos, un .sav y un .txt.
Si abrimos una consola de Jupyter Notebook en esta carpeta
Corremos una nueva terminal de Python
Ahora podemos intentar leer el archivo con read_csv
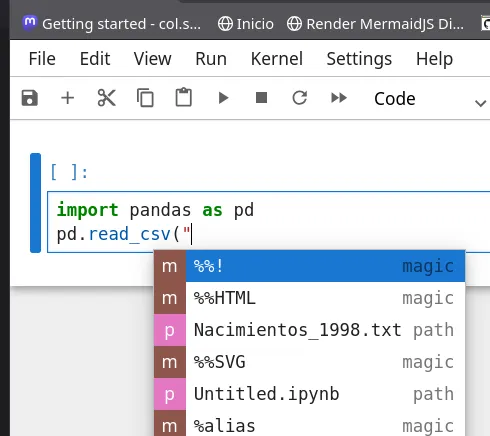
Este archivo tiene una inconsistencia en su nombre, debería tener extensión .csv. Por ahora no nos preocupemos por eso. Si lo intentamos cargar con la instrucción:
df=pd.read_csv("Nacimientos_1998.txt")
Tenemos un error (largo), que al final dice:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd1 in position 73589: invalid continuation byte
Lo que está indicando es que hay un error de codificación. Las opciones de codificación que usualmente funcionan son:
ISO-8859-1
latin1
utf-8
ascii
Cambiamos la instrucción a:
df=pd.read_csv("Nacimientos_1998.txt",encoding='ISO-8859-1')
Muestra el siguiente error:
ParserError: Error tokenizing data. C error: Expected 1 fields in line 2764, saw 3
Dice que esperaba “1 campo”, es decir variable, y encontró “3”. Es un error del separador, dado que esperamos que haya más de 1 variable. Si hacemos click con el botón secundario e intentamos abrir el archivo con bloc de notas, vemos lo siguiente:
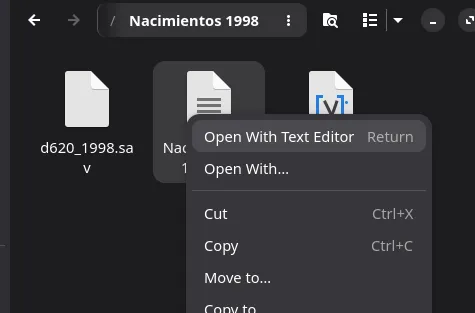
Se ve que el archivo no está separado por comas o punto y coma si no por tabuladores. Cambiamos la instrucción a:
df=pd.read_csv("Nacimientos_1998.txt",encoding='ISO-8859-1',sep="\t")
Lo que estamos diciendo es: cargue el archivo llamado “Nacimientos_1998.txt”, trátelo como si fuera un archivo separado por tabulador, use la codificación ISO 8859, asígnelo al DataFrame que llamamos df. No hay nada importante en ese nombre, podríamos usar otro.
El procedimiento ha sido un poco largo, pero solucionamos varios problemas de lectura de datos. De aquí en adelante ya podemos usar las herramientas de pandas, entonces el trabajo será más sencillo.
Se pueden averiguar las características de los DataFrame así:
-
Su forma, en (filas,columnas), con:
df.shape.Ejemplo: en nuestro caso,
(720984, 33), luego son 720984 registros de 33 variables. -
Los nombres de las columnas:
df.columnsEjemplo: en este caso:
Index(['cod_dpto', 'cod_munic', 'areanac', 'sit_parto', 'nom_inst', 'cod_inst', 'sexo', 'peso_nac', 'talla_nac', 'ano', 'mes', 'aten_par', 't_ges', 'numconsul', 'tipo_parto', 'mul_parto', 'apgar1', 'apgar2', 'gru_san', 'edad_madre', 'est_civm', 'niv_edum', 'codpres', 'codptore', 'codmunre', 'area_res', 'n_hijosv', 'fecha_nacm', 'n_emb', 'seg_social', 'edad_padre', 'niv_edup', 'profesion'], dtype='object') -
Los primeros registros:
df.head(), por defecto saca 5, pero se puede cambiar.Ejemplo: en este caso:
cod_dpto cod_munic areanac sit_parto nom_inst cod_inst sexo ... n_hijosv fecha_nacm n_emb seg_social edad_padre niv_edup profesion
0 27 6 1 1 HL LASCARIO BARBOZA A 270060013.0 1 ... 1 NaN 1 9 15 9 1
1 27 73 1 1 CSCC BAGADO 270730019.0 2 ... 99 NaN 99 9 99 9 2
2 27 75 2 2 NaN NaN 2 ... 1 NaN 1 9 25 2 3
3 27 361 2 1 CS ANDAGOYA 273610065.0 1 ... 1 NaN 1 9 19 3 1
4 27 361 2 1 CS ANDAGOYA 273610065.0 2 ... 1 NaN 1 9 33 3 1
[5 rows x 33 columns]
I
- Los últimos registros:
df.tail()
Out[14]:
cod_dpto cod_munic areanac sit_parto nom_inst cod_inst sexo peso_nac ... area_res n_hijosv fecha_nacm n_emb seg_social edad_padre niv_edup profesion
720979 73 168 1 2 NaN NaN 2 9 ... 9.0 99 NaN 99 9 99 9 9
720980 17 524 1 2 NaN NaN 2 9 ... 9.0 99 NaN 99 9 48 9 4
720981 70 124 9 2 NaN NaN 1 9 ... 9.0 99 NaN 99 9 33 9 9
720982 13 760 9 2 NaN NaN 1 9 ... 9.0 99 NaN 99 9 99 9 9
720983 76 606 9 9 NaN NaN 1 9 ... 9.0 99 NaN 99 9 99 9 4
[5 rows x 33 columns]
Accediendo a variables (columnas) de un DataFrame
En principio, cada columna corresponde a una variable.
Para acceder a los registros se puede:
-
Usar corchetes
[], dentro de los cuales se escribe el nombre de la columna. -
Usar el punto, seguido del nombre de la columna.
Funciones sobre las variables de un DataFrame
Estas funciones son comunes a numpy, entonces no son únicas de los DataFrames, pero para nosotros basta con mencionarlas aquí. Mencionamos unas pocas, hay muchas más. Revisar la bibliografía de numpy y pandas.
-
unique: indica los valores que están en un conjunto de datos.
-
Por ejemplo en la lista: [1,1,1,3,1,2], los valores que están son 1,2,3
-
En el DataFrame que estamos usando, existe una variable llamada
cod_dpto, que corresponde al código del departamento. Si queremos saber cuáles códigos de departamento están en el conjunto de datos que tenemos, podemos teclear:df.cod_dpto.unique()en este caso se obtiene:
array([27, 52, 66, 63, 73, 95, 19, 17, 8, 20, 88, 70, 44, 47, 13, 81, 54, 68, 5, 23, 76, 86, 15, 41, 50, 25, 18, 85, 11, 94, 91, 99, 97])lo que quiere decir que usamos la función
unique, en la columna (variable)cod_dpto, y obtuvimos como resultado un arreglo con esos valores.
-
-
min: indica el valor mínimo.
- Ejemplo:
df.cod_dpto.min()
- Ejemplo:
-
max: indica el valor máximo
- Ejemplo:
df.cod_dpto.min()
- Ejemplo:
-
otras funciones estadísticas, como
kurt()para la curtosis,skew()para la asimetría,mean()para el promedio aritmético ymode()para la moda, entre otras.
Consultas de bases de datos usando librerías. Filtros (por index, variables y casos) y ordenación4
Como parte de la etapa de Procesamiento de la Información de la codificación en Python, puede ser necesario filtrar una parte del conjunto de datos. Como ejemplo, pensemos en el conjunto de datos de la instrucción anterior. Su descripción está en la página del DANE de la que lo bajamos: https://microdatos.dane.gov.co/index.php/catalog/366/study-description. Allí nos informan que el conjunto de datos tiene información sobre las estadísticas de nacimientos y defunciones, producidas por el DANE, con información de la Registraduría, y basándose en el certificado nacido vivo, diligenciado por personal médico que atiende el hecho vital. Las variables quedan descritas en https://microdatos.dane.gov.co/index.php/catalog/366/data-dictionary/F1?file_name=Nacimientos_1998, donde indican que la variable cod_dpto hace referencia a un código de departamento, y la variable cod_munic a un código de municipio. Luego si quisiéramos referirnos sólo a la los nacimientos que ocurrieron en un departamento particular debemos filtrar por valores de una de éstas variables.
Filtros
Se pueden filtrar valores con los operadores lógicos. Por ejemplo, para filtrar todos los nacimientos en que el código de municipio es 88 se crea primero un vector que indique si el código es ese:
filtro1 = df.cod_munic == 88
Y ahora se usa para filtrar
muncod88 = df[filtro1]
Si queremos usar dos filtros, podemos usar el operador & para unir dos vectores de filtro:
filtro2 = (df.cod_munic == 88) & (df.cod_dpto ==5)
Y luego podemos filtrar con este vector
m88d5 = df[filtro2]
Datos Faltantes
Según Chen et al., existen tres tipos de datos faltantes:
-
Datos faltantes distribuidos completamente al azar. Los datos faltantes de una variable no están relacionados con las demás variables del conjunto de datos. Usualmente esto no afecta el análisis.
-
Datos faltantes distribuidos al azar. Los datos faltantes dependen de otra variable. Por ejemplo, quienes no responden una pregunta de ingreso tienden a tener un bajo nivel educativo. Aquí normalmente es a lugar hacer un ajuste.
-
Datos faltantes no distribuidos al azar. Los datos faltantes se correlacionan con un concepto medido. Por ejemplo, las personas pueden no responder a la pregunta sobre el ingreso porque tienen altos ingresos. En estos casos se requiere conocer profundamente la teoría relacionada con la encuesta para poder analizar.
Además proponemos la siguiente categoría:
- Datos faltantes no necesarios. Cuando no se registra el valor porque la definición de la variable o de otra variable implica que el dato mismo no tiene sentido. Por ejemplo, a un bebé no se le pregunta si ha tenido hijos.
Estrategias para identificar datos faltantes
(ésta sección sigue la teoría en VanderPlas)
Existen diferentes estrategias para indicar la presencia de datos
faltantes en las tablas o DataFrames. Ninguna de éstas estrategias
es perfecta.
máscaras (del inglés mask)
Se genera un arreglo booleano separado, o una representación en la tabla para indicar el estado nulo del valor.
Como desventajas de ésta estrategia está el que su implementación requiere más espacio para guardar el arreglo de máscara.
valores sentinel (del inglés sentinel value)
Los valores faltantes se remplazan por un valor específico, por
ejemplo se usa un valor negativo como -999, u otro valor específico
diferente a los datos presentes, o una convención global como el uso
de la clase NaN.
Como desventajas tenemos que la presencia de éstos valores puede generar errores al calcular agregados.
En Pandas
Pandas implementa la estrategia de valores sentinel, específicamente
al generar un DataFrame en pandas en la que haya datos faltantes se
usan dos tipos de dato nulo que existen previamente en Python: NaN y
None.
import pandas as pd
import numpy as np
Ejemplos:
-
None:vals1 = pd.Series([1, None, 3, 4]) -
NaNvals2 = pd.Series([1, np.nan, 3, 4])
Operaciones sobre valores nulos
-
isnull(): genera un arreglo booleano que indica cuáles valores son faltantes. Ejmplo:vals1.isnull() 0 False 1 True 2 False 3 False dtype: boolEjercicio: si tenemos el arreglo:
data = pd.Series([1, np.nan, 'hello', None])Ejecute la funciónisnulldelDataFramedata. Describa el resultado de la operación1. -
notnull(): lo opuesto aisnull(), un arreglo booleano que indica cuáles valores no son faltantes. Ejemplo: vals1.notnull()0 True 1 False 2 True 3 True dtype: boolEjercicio, haga lo propio ahora para ésta función, sobre
data -
dropna(): devuelve un nuevo arrreglo, al que se le filtran los datos faltantes. Por defecto la función remueve todas las filas en las que haya por lo menos un dato faltante.Ejemplo:
vals1.dropna() 0 1.0 2 3.0 3 4.0 dtype: float64Ejercicio: definamos un
DataFramecon datos faltantes:df = pd.DataFrame([[1,np.nan, 2], [2,3,5], [np.nan, 4,6]])Piense (no lo ejecute todavía). ¿qué valores quedarían marcados como
Truesi ejecutásemos la funciónisnull? Compruébelo.Responda. ¿Que pasaría si ejecutáse la función
dropna? específicamente, ¿cambiadf? Compruébelo.Las opciones de
dropnason:axispara indicar si se remueven filas o columnas, con valoresrows(el valor por defecto) ocolumns;howpara indicar el criterio para remover, con el valoranypara remover ejes que tengan por lo menos un valor nulo, oallpara requerir que todos los valores del eje sean nulos; ythreshpara identificar el mínimo número de valores no nulos que hacen que se mantenga la columna.Ejercicio: juegue con las opciones, pensando qué va a pasar antes de ejecutar la función.
-
fillna(): devuelve una copia del arreglo, con valores imputados para los faltantes. Ejercicio: revise con la ayuda dePythoncuáles son las openciones para ésta función.
Ejercicio
-
Descargue el archivo de nacimientos del año 1998 del portal del DANE
-
Cargue los datos a un DataFrame, llamado df98.
AYUDA: Si usó la página del DANE la codificación es
ISO-8859-1y el separador es el tabular,\tpd.read_csv("Nacimientos_1998.txt",encoding='ISO-8859-1',sep="\t") -
Extraiga una serie de datos para la variable de
nom_inst:serienombre = df98[‘nom_inst’]
-
¿Cómo encontraría cuántos datos faltan para la variable serienombre?
-
Usando df98, construya un dataframe que sólo tenga registros completos. Llámelo
df98filtrado. -
Con
df98filtrado, haga un histograma del código de departamento.
Ejercicio
Quiero construir un histograma de las edades del padre. Revisando la descripción de los datos, he encontrado que hay un código de máscara. Ahora, podría pasar que, addemás de esta máscara, haya otros tipos de datos faltantes.
- Identifique si hay datos faltantes en la variable edad del padre.
- Cree una nueva variable que marque los valores de la máscara
- Filtre el conjunto de datos para tener sólo valores en los cuales existe el dato de edad del padre
Modificaciones Sobre las variables
Una vez se ha identificado problemas en los registros, ya sea por valores faltantes, valores sentinela o tipos de datos diferentes, hay varias estrategias que se pueden usar para trabajar con estos datos.
Generar Nuevas Columnas
Se puede generar una nueva columna de un DataFrame símplemente usando el nombre nuevo de la columna. Por ejemplo, si tenemos el siguiente DataFrame llamado notas:
notas = pd.DataFrame({'Name': ['Claudia', 'Pedro', 'Juan', 'Adriana', 'Laura'],
'Código': [1, 4, 5, 6, 10],
'Nota1': [93, 55, 89, 79, 89],
'Nota2': [78, 45, 99, 80, 81]})
Para generar una nueva columna que tenga el promedio de las columnas Nota1 y Nota2, lo podemos hacer de la siguiente forma:
notas['promedio'] = (notas['Nota1'] + notas['Nota2'])/2
En ésta fórmula se toma la suma de las dos columnas, dividida entre dos, y se le asigna a la nueva variable promedio.
Crear una Serie de un tipo dado
Para crear una serie, basada en una serie existente, cambiando el tipo, se usa el método .astype. Por ejemplo, en el arreglo notas la variable Código es numérica:
notas.Código
Genera:
0 1
1 4
2 5
3 6
4 10
Name: Código, dtype: int64
Aquí indica que el tipo es int64. Podríamos querer que en lugar de los valores de un dígito se reporten como dos dígitos, con un cero, tenemos que usar la columna tipo texto. La serie tipo caracter, se crea así:
notas.Código.astype("str")
Si además queremos añadir los ceros, usamos:
notas.Código.astype("str").str.pad(2,fillchar='0')
Aquí se indica que la variable es de 2 caracteres y que se llena con ceros. Finalmente se crea la nueva columna:
notas['cod']=notas.Código.astype("str").str.pad(2,fillchar='0')
Seleccionar registros usando el método loc
El método loc permite identificar los valores de un arreglo por su índice.
Por ejemplo, si queremos identificar los valores de las notas mayores a 60:
notas.loc[notas["promedio"]>60,"aprueba"] = True
notas.loc[notas["promedio"]<=60,"aprueba"] = False
Aquí el .loc indica que se trabaja con los registros de la columna promedio. Si el valor es mayor a 60, se asigna True, si es menor o igual, se asigna False a la variable “aprueba”. Si no se incluye el nombre de la variable se cambiarían todos los valores del registro.
Ejercicio
- Cargue los datos de la base de nacimientos del dane para el año 98.
- Identifique la columna
edad_padre. Si el valor es 99, cambíelo porpd.Na. - Identifique la columna
cod_munic. Construya una nueva variable del mismo DataFrame, que sea de 3 caractéres, de tipo texto, llenándo con 0. Llámelacód_mun_str. - Identifique la comuna
cod_dpto. Construya una variable del miso DataFrame, de topo texto, 2 caracteres, llena con 0, llamelacod_dpto_str - Genere una nueva variable, llamada código, que sea el resultado de unir las variables
cód_mun_strycod_dpto_str.
Bibliografía para esta sección
-
Python Data Science Handbook. Jake VanderPlas.
-
Data Science for Public Policy. Chen, Rubin, Cornwall.
-
https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html
-
https://www.geeksforgeeks.org/python/how-to-fix-settingwithcopywarning-in-pandas/
Operaciones con bases de datos: fusionar y unir, aplicar operaciones
Concatenar
Si A y B son objetos organizados, concatenar A y B consiste en crear un nuevo objeto C con los registros de A y B; organizados secuencialmente.
Ejemplo
Primero importamos la librería:
import pandas as pd
Ahora, dados:
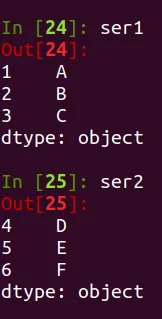
ser1 = pd.Series(['A', 'B', 'C'], index=[1, 2, 3])
ser2 = pd.Series(['D', 'E', 'F'], index=[4, 5, 6])
¿Qué tipo de estructura de datos son? ¿Cómo espera que se muestren en Python?
Concatenar las Series
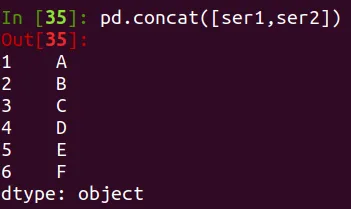
pd.concat([ser1,ser2])
Si las series son las siguientes:
Se pueden concatenar de la siguiente manera:
DataFrames con las mismas variables
Concatenar dos DataFrames. Los definimos (usualmente usted los lee de un archivo):
df1=pd.DataFrame([['A1','B1'],['A2','B2']],
columns=['A','B'],index=[1,2])
df2=pd.DataFrame([['A3','B3'],['A4','B4']],
columns=['A','B'],index=[3,4])
Los concatenamos con el comando pd.concat:
![Impresión de pantalla. El comando es dfc=pd.concat([df1,df2]). El resultado es una tabla con las columnas A y B, y su primer registro es A1,B1](/_astro/dfconcat.B6cnkeeD_ZNCjUu.webp)
Usualmente no nos interesa preservar el índice, luego usamos la opción
ignore_index=True, para que se reasigne el índice:
![Impresión de pantalla. Primero está la instrucción pd.concat([df1,df2],ignore_index=True), seguido por una tabla con las variables A, B, y cuyo primer registro es A1,B1.](/_astro/dfcignoreindex.GUUm5PUa_Z1Y6mLM.webp)
DataFrames con diferentes variables
Concatenar dos DataFrames
Los definimos (usualmente usted los lee de un archivo):
df5=pd.DataFrame([['A1','B1','C1'],['A2','B2','C2']],
columns=['A','B','C'],index=[1,2])
df6=pd.DataFrame([['B3','C3','D3'],['B4','C4','D4']],
columns=['B','C','D'],index=[3,4])
Imprímalos. ¿Qué variables tiene df5?
¿Qué variables tiene df6?
Podemos usar el atributo .columns, así: `df5.columns’.
¿Que cree que puede pasar al concatenar los dos DataFrames?
Concatenar Uniendo los conjuntos de variables
El DataFrame, mezcla de df5 y df6, tiene todas las variables (aquí ,,,.):
pd.concat([df5,df6],join='outer')
‘outer’ es el valor por defecto de join, es equivalente a
pd.concat([df5,df6])
Se obtiene lo siguiente:
![Impresión de pantalla. Primero está la instrucción pd.concat([df5,df6]), cuyo resultado es una tabla con las variables A,B,C,D. El primer registro es A1,B1,C1,NaN. La segunda instrucción es pd.concat([df5,df6],join='outer'), el resultado es una tabla con las variables A,B,C,D. El primer registro se sde nuevo A1,B1,C1,NaN](/_astro/outerconcat.BXAb9YkG_Z2re3RI.webp)
Intersectando conjuntos de variables
El DataFrame, mezcla de df5 y df6, tiene sólo las que están en ambos (en este caso, y .):
![Impresión de pantalla de código. Está la instrucción pd.concat([df5,df6],join='inner') y luego el resultado de esa instrucción, que es una tabla con las variables "b" y "C".](/_astro/innerconcat.DTb2L_sP_ZMQCYm.webp)
Combinar DataFrames: Merge y Join
Merge: Uno a Uno
Supongamos que se tienen los siguientes conjuntos de datos (organizados en DataFrames):
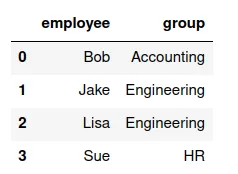
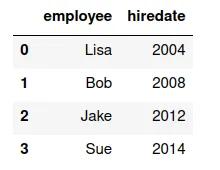
un (valor de la variable) a un(valor de la variable)
Un merge uno a uno consiste en crear un nuevo conjunto de datos (DataFrame, tabla) que tenga los valores del primero apareados con los valores de la segunda.
¿Cuáles son las variables de df7?
¿Cuáles son las variables de df8?
Si queremos un DataFrame que tenga las variables 'employee','hiredate','group', debemos mezclar, aparear, df7 y df8.
merge
El comando mergede Python aparea automáticamente si hay una variable compartida en los dos DataFrames. El código sería el siguiente. Primero generamos el conjunto de datos df7 y el conjunto de datos df8:
df7 = pd.DataFrame({'employee': ['Bob', 'Jake', 'Lisa', 'Sue'],
'group': ['Accounting', 'Engineering', 'Engineering', 'HR']})
df8 = pd.DataFrame({'employee': ['Lisa','Bob','Jake','Sue'],
'hiredate': [2004,2008,2012,2014]})
Y luego hacemos el merge:
dfm = pd.merge(df7,df8)
print(dfm)
El resultado es el siguiente:
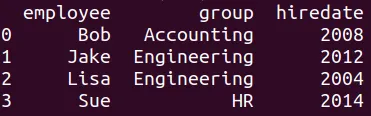
Tenga en cuenta que:
-
No importa que los registros no estén en el mismo orden
-
Usualmente se descarta el índice.
Merge: Muchos (valores de la variable) a Un (valor de la variable)
Vamos a trabajar con el conjunto dfmque habíamos generado anteriormente, y un nuevo conjunto df9:
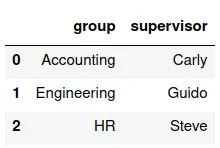
¿cuál sería el código para asignar los datos de esa tabla a la variable df9?
Muchos a Uno
Se trata de unir dos DataFrames, en el caso en que uno de ellos tiene registros que repiten el mismo valor de la variable.
En éste caso, ¿Qué variable de dfm tiene valores repetidos en diferentes registros?
merge
Al mezclar dfm y df9 Python crea un nuevo conjunto de datos, para el cual a cada registro se le asigna la variable supervisor, apareando de las dos tablas anteriores. Hagamos el merge, asignémoslo a la variable df9, e imprimamos el resultado de la operación.
dfm3 = pd.merge(dfm,df9)
print(dfm3)
El resultado es el siguiente
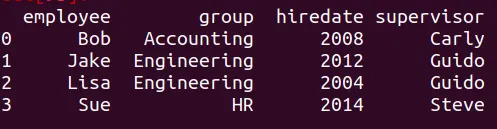
Merge: Muchos a Muchos
Supongamos que tenemos los siguientes conjuntos de datos.
Primero df7 es:
Y df10 es:
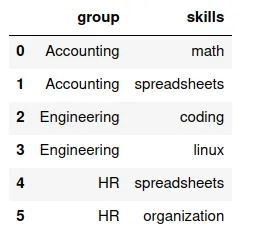
Escriba el código para generar estas dos tablas.
¿Qué variable comparten los DataFrames?
¿Que espera que pase al mezclarlos?
Muchos-a-Muchos
Se trata de un apareamiento muchos-a-muchos porque en ambos DataFrames hay variables que tienen registros repetidos.
merge
El código para mezclarlos es:
dfm2 = pd.merge(df7,df10)
Y se puede imprimir el resultado con:
print(dfm2)
En este caso el resultado es:
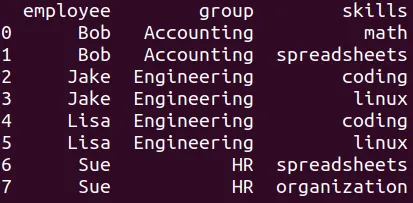
Por cada valor de skills hay un registro, así se repitan los valores de las variables employee y group.
Ejercicio
Pregunta
Tenemos dos archivos con información de la interacción de personas con el Estado. Para la primera etapa del concurso, queremos generar una tabla que indique si las personas inscritas tienen o no tienen sanción disciplinaria; para informarles si por lo tanto suplen ese requisito. En la primera base df1 tenemos la variable “número-de-cédula” y tipo-de-trámite, que indica qué solicitaron al llenar el formulario. En la segunda base, df2, tenemos la variable número-de-cédula y la variable sanción, que indica si la persona tiene o no sanción disciplinaria.
¿Qué operación/operaciones haría para generar una base que incluya únicamente a quienes quieren participar en el concurso, indicando si tienen o no sanción disciplinaria?
A. Filtrar por valores en df1, Concatenar las dos bases.
B. Filtrar por valor de la variable sanción en df2, unir con merge las dos bases.
C. Filtrar por valor de la variable tipo-de-trámite en df1, unir con merge las dos bases.
D. Filtrar por valores en df2, Concatenar las dos bases.
Casos Especiales
Renombrar Variables
Si queremos renombrar las variables de un DataFrame, podemos usar el método .rename()
Por ejemplo, si tenemos el siguiente DataFrame, llamado df12:
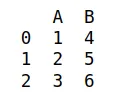
Podemos querer cambiar el nombre de las variables (mayúscula a minúscula). Se puede hacer así:
df12.rename(columns={"A": "a", "B": "b"})
¡Atención! Por defecto la función devuelve un nuevo DataFrame. Para alterar el que tenemos, use la opción inplace.
df12.rename(columns={"A": "a", "B": "b"}, inplace=True)
Es decir:
![Impresión de pantalla. Primero está la instrucción para generar df12: df12=pd.DataFrame({"A":[1,2,3],"B":[4,5,6]}). Luego está la instrucción para renombrar, df12.rename(columns={"A": "a", "B": "b"}).](/_astro/ejemplorename.C_EyAycQ_ZEJKfe.webp)
Especificar la columna a usar de clave para mezclar
Si los DataFrames comparten diversas variables, podemos usar la opción on para especificar cuál variable usar como clave para mezclar.
EJEMPLO
Si el df13 es el siguiente:

Y df14 el siguiente:
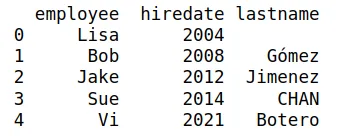
¿qué variables son comunes entre los dos DataFrames?
Si hacemos el merge debemos especificar cuál de las variables se usa para mezclar. Por ejemplo puede ser employee. La instrucción:
pd.merge(df13,df14,on='employee')
El resultado es una nueva base, que usa como llaves la columna employee y tiene las variables de los dos conjuntos de datos anteriores. Como tenemos dos veces la variable lastname, una por conjunto, aquí nos saldrá repetida, es decir lastname_x es la del primer conjunto y lastname_y la del segundo.
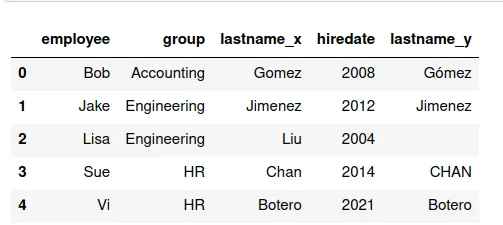
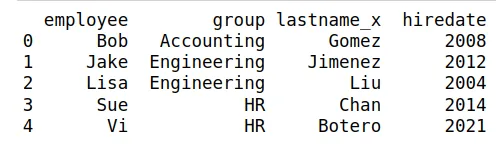
De nuevo, se puede remover la variable duplicada con el método .drop:
df15 = pd.merge(df13,df14, on="employee")
df15 = df15.drop("lastname_y", axis=1)
print(df15)
Produce la siguiente tabla:
Especificar columnas diferentes en DataFrames
Podemos especificar diferentes variables para cada DataFrame. Aquí el primero será left_on y el segundo será right_on.
Supongamos que tenemos el df11:
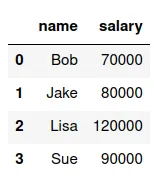
Una forma de ingresar este DataFrame es el siguiente código:
df11=pd.DataFrame({'name': ['Bob', 'Jake', 'Lisa', 'Sue'],
'salary': [70000, 80000, 120000, 90000]})
El df7 es el que ya teníamos:
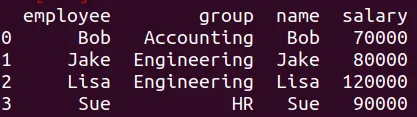
Los DataFrames df11 y df7 tienen variables con la misma información pero diferente nombre de variable. Podemos mezclar, pero debemos especificar cuáles son las variables. La instrucción es:
pd.merge(df7,df11,left_on="employee",right_on="name").drop("name",axis=1)
Se obtiene la siguiente tabla:
Inner - Outer - Left - Right
Volvamos a pensar en que pasa cuando existen valores de los registros que no se encuentran en ambos DataFrames.
Tomemos los siguientes conjuntos de datos, llamados df13:
y df16:

¿Qué cree que pasa si mezclamos estos dos DataFrames?
inner
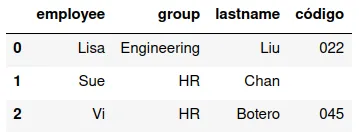
Intersecta los conjuntos, es decir, produce un DataFrame que tiene sólo registros que tienen valores de variables en ambos DataFrames:
pd.merge(df13,df16,how="inner")
Devuelve un DataFrame que sólo tiene los valores para los cuales la llave está en ambos.
outer
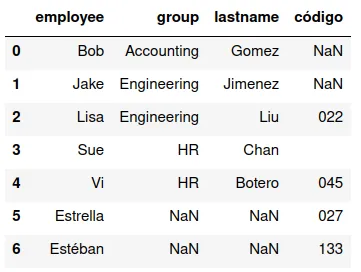
Une los conjuntos, es decir, produce un DataFrame que tiene todos registros que tienen valores de variables en alguno de los DataFrames. Los valores faltantes los llena con NAs. En este ejemplo la instrucción sería:
pd.merge(df13,df16,how='outer')
Y se obtiene:
Merge a la izquierda (primer DataFrame) y a la derecha (segundo)
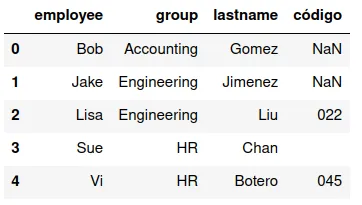
left
Si hay dos conjuntos de llaves, y difieren en algunos valores de la variable, se puede usar los registros que corresponden a los valores de la variable del primer DataFrame.
En el ejemplo que hemos trabajado, la instrucción sería:
pd.merge(df13,df16,how='left')
Y produciría el siguiente conjunto de datos:
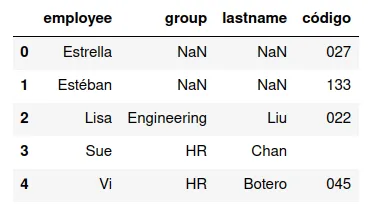
right
Si hay dos conjuntos de llaves, y difieren en algunos valores de la
variable, se puede usar los registros que corresponden a los valores
de la variable del segundo DataFrame.
pd.merge(df13,df16,how="right")
Y produciría el siguiente conjunto de datos:
Ejercicio
Mezclar las bases de datos del DANE de Nacimientos
Vamos a trabajar con la base que ya habíamos bajado anteriormente (Nacimientos para el año 1998), además de una nueva.
- Intente buscar en internet el enlace para Estadísticas Vitales 2021
- OK, éste es el enlace: https://microdatos.dane.gov.co/index.php/catalog/775/get-microdata
- Descargue - Organice - Renombre - Registre los cambios
- Cargue ambos
DataFrames, tanto el del 98 que ya había usado, como éste del 21. En Python llámelosdatos98ydatos21
- Imprima los nombres de variables (columnas) de ambos
DataFrames. ¿Qué similitudes encuentra? ¿Qué diferencias encuentra?
- ¿cómo averiguaría cuántos registros hay en el 98 y cuantos en el 21?
- Si queremos un
DataFramepara el cual sólo vamos a comparar el peso de neonatos entre el 98 y el 21, ¿cuál es la forma más sencilla de hacer eseDataFrame?
- Si queremos comparar las variables Edad de la Madre, Edad del Padre, Peso al Nacer, talla, entre los dos años; y para eso hacemos un nuevo
DataFrame, ¿que deberíamos hacer?
Transformación y reporte de la información de los conjuntos de datos
La razón para ingresar la información a Python es la de utilizar los métodos de la estadística descritpiva y el análisis de datos para poder comprender los fenómenos asociados a éstos datos. Inicialmente veremos cómo llevar a cabo análisis descriptivos básicos, seguido de operaciones sobre las tablas.
Agregados
Comenzamos con estadísticos básicos, como los estadísticos de centro y variabilidad. Por ejemplo, trabajemos con la base de datos que acabamos de incluir en el ejemplo anterior. Podemos cargar la librería pandas, leer el archivo y generar un DataFrame con el nombre df21 y luego proceder a filtrar algunas columnas de éste:
import pandas as pd
df21 = pd.read_csv("nac2021.csv",encoding="ISO-8859-1")
df21 = df21[['SEXO','PESO_NAC','EDAD_PADRE']]
Ahora podemos agregar algunos valores. Por ejemplo, si queremos saber la suma de las edades de todos los padres podemos usar el siguiente comando:
print(df21.EDAD_PADRE.sum())
Si todos los datos son numéricos, podemos pedir la suma de todas las variables del DataFrame:
df21.sum()
Ahora, el que podamos no significa que debamos. Por ejemplo, podemos calcular el promedio de éstos datos:
df21.mean()
Aquí obtenemos:
SEXO 1.487908
PESO_NAC 5.736197
EDAD_PADRE 37.662870
dtype: float64
Aquí hay varios problemas. Es importante revisar el diccionario de datos: https://microdatos.dane.gov.co/index.php/catalog/775/data-dictionary/F31?file_name=nac2021 para identificar características de éstos datos. La primera variable, SEXO es una variable categórica que está identificando con 1 a hombres y 2 a mujeres. Por lo tanto, aunque sea numérica, no tiene sentido hacer un promedio. Algo similar pasa con la variable PESO_NAC, donde los números corresponden a categorías de peso.
Para el caso de EDAD_PADRE en principio tenemos una variable cuantitativa que registra la edad. Ahora, dado que el DANE usa el método de valor sentinel para marcar datos faltantes, es posible que al calcular el promedio se esté tomando valores que no corresponden a la realidad. Para identificar si éste es el caso podemos hacer uso de la función unique, presentada anteriormente. Así:
edades= df21.EDAD_PADRE.unique()
edades.sort()
print(edades)
Aquí obtenemos las edades ordenadas. La salida del comando es la siguiente:
[ 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48
49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66
67 68 69 70 71 72 73 74 75 76 77 78 79 80 999]
Se puede ver que hay un valor de 999, que revisando la operación estadística podemos ver que corresponde a los datos faltantes.
Ejercicio
Usando lo que habíamos aprendido antes, construya un filtro para no tener en cuenta los valroes para los que no hay dato de edad, es decir para los que se tiene el valor sentinel de 999. Calcule el promedio del nuevo conjunto de datos.
Lista de funciones agregadoras
Aquí reproducimos la tabla de VanderPlas, con las funciones agregadas. Tenga en cuenta que la version NaN filtra automáticamente los valores NaN al hacer el cálculo.
| Nombre de la función | Versión NaN | Descripción |
|---|---|---|
| np.sum | np.nansum | Calcular la suma de los valores |
| np.prod | np.nanprod | Calcula el producto de los valores |
| np.mean | hnp.nanmean | Calcula el promedio aritmético |
| np.std | np.nanstd | Calcula la desviación estándar |
| np.var | np.nanvar | calcula la varianza |
| np.min | np.nanmin | Halla el valor mínimo |
| np.max | np.nanmas | Halla el máximo |
| np.argmin | np.nanargmin | Halla el índice del mínimo |
| np.argmin | np.nanargmin | Halla el índice del mínimo |
| np.median | np.nanmedian | Halla la mediana del conjunto de valores |
| np.percentile | np.nanpercentile | Halla los percentiles |
| np.any | Evalúa si algún elemento es True | |
| np.all | Evalúa si todos los elementos son True | |
| 5 |
Factores de Expansión
Para construir una encuesta se siguien los siguientes pasos.
- Se define el tamaño de la muestra.
- Se eligen los individuos aleatoriamente.
- Se corrijen los datos usando un factor de expansión.
El tamaño adecuado de la muestra busca garantizar que hay suficientes individuos como para representar a la población total, pero al mismo tiempo asegurando que el proceso es eficiente en recursos.
La elección aleatoria de los individuos sirve para evitar sesgos de selección. Por ejemplo piense en el fenómeno conocido como la “cámaras de eco” o “burbujas informativas”, en el que pensamos que todas las personas piensan de una manera únicamente porque quienes están a nuestro alrededor lo hacen así.
Esto lleva a que la muestra elegida no necesariamente tenga la misma fracción de las personas con ciertas características que la población general.
Como ejemplo, una encuesta puede tener 3000 formularios, de los cuales la distribución de la varaible “sexo” es la siguiente:
| sexo | Porcentaje en Muestra | Porcentaje en Pobalcion |
|---|---|---|
| H | 40.47 | 49 |
| M | 59.53 | 51 |
Ahora, si queremos calcular promedios de otras variables de la muestra, vamos a tener un problema de subrepresentación de “H” contra “M” en nuestra muestra. En ese caso se corrije el cálculo usando los factores de expansión, que se calculan como el inverso de la probabilidad de selección de las unidades de muestreo.
Dicho de otra forma, cada uno de los cuestionarios de la muestra representa un número de personas en la población igual al factor de expansión.
Esto quiere decir que si tenemos una variable , que toma los valores en la muestra, y un factor de expansión para cada dato , el promedio sobre la población de la variable A se calcula de la siguiente forma:
Dicho de otro modo, los promedios de la variable son sumas de la variable multiplicada por el factor de expansión y dividido por la suma de los factores de expansión.
Ejemplo pobreza monetaria 2022
Tomemos como ejemplo los datos del “Medición de Pobreza Monetaria y Desigualdad 2022”, publicados por el DANE en: https://microdatos.dane.gov.co/index.php/catalog/804/study-description. Podemos hacer la descarga de los datos del módulo “Personas” y cargar el Archivo csv a Pandas. La recomendación es cambiar el nombre de la carpeta de POBREZA.csv a personas_pobreza-monetaria-22. Luego cargamos los datos:
import pandas as pd
df22 = pd.read_csv("personas_pobreza-monetaria-22/PERSONAS.csv")
Vamos a trabajar con las siguientes variables:
- clase 1. Cabecera, 2. Resto (centros poblados y área rural dispersa) (clase)
- p6040 ¿cuántos años cumplidos tiene? (p6040)
- p3271 Sexo (p3271)
- p3042 ¿Cuál es el nivel educativo más alto alcanzado por … y el último año o grado aprobado en este nivel? (p3042)
- ingtot ingreso total
- fex_c Factor de expansión anualizado (fex_c)
Primero generamos un subconjunto de datos que tenga únicamente estas variables, y limpiamos de datos faltantes:
df = df22[["clase","p6040","p3271","p3042","ingtot","fex_c"]]
dfl = df.dropna()
Podemos buscar el mínimo y máximo del ingreso total:
print(dfl.ingtot.max())
print(dfl.ingtot.min())
Ahora, generamos una variable que corresponde al ingreso, multiplicado por el factor de expansión, y calculamos el tamaño de la población:
dfl["ingexp"] = dfl.ingtot*dfl.fex_c
poblacion = sum(dfl.fex_c)
Es decir, la muestra está representando una población de 38 656 558. El ingreso promedio de la población se calcula de la siguiente forma:
ingprom = sum(dfl.ingexp)/poblacion
Agregar y Agrupar
Además del uso de funciones como sum, pandas tabién provee agregación con la función describe. Por ejemplo, para el dataframe df21 que generamos anteriormente, tenemos lo siguiente:
df21.describe()
Genera la siguiente tabla:
| SEXO | PESO_NAC | EDAD_PADRE | |
|---|---|---|---|
| count | 616914.000000 | 616914.000000 | 616914.000000 |
| mean | 1.487908 | 5.736197 | 37.662870 |
| std | 0.500026 | 1.115809 | 86.917286 |
| min | 1.000000 | 1.000000 | 13.000000 |
| 25% | 1.000000 | 5.000000 | 24.000000 |
| 50% | 1.000000 | 6.000000 | 29.000000 |
| 75% | 2.000000 | 6.000000 | 35.000000 |
| max | 3.000000 | 9.000000 | 999.000000 |
Los estadísticos que genera esta tabla son útiles para describir los datos. Por ejemplo, la mediana de edad del padre es 29, y el tercer percentil de PESO corresponde a la categoría marcada como 6.