Table of contents
Open Table of contents
Tipos de distribuciones
Distribuciones Continuas
Variable continua
Las variables continuas toman valores en los números reales. Representan cantidades cuya medición puede ser un valor decimal,
Ejemplo: variable peso-al-nacer
En una base de datos se registran el peso al nacer de los neonatos. Se pesan con una balanza con una precisión de 0.001 kg (es decir 1g); por lo tanto la variable “peso del neonato” es continua.
Función de densidad de probabilidad de una variable continua
Cuando la variable es continua, no tiene sentido hablar de la probabilidad de que se obtenga un valor exacto. En su lugar se habla de la probabilidad de que una variable tome un valor en un intervalo. La función densidad de probabilidad tiene las siguientes características:
-
La función de probabilidad es positiva.
-
. El área bajo la curva de la densidad de probabilidad es 1.
-
. La probabilidad de un evento entre y es la integral entre esos dos valores.
Distribución uniforme continua
Dada una variable , que puede tomar valores en el intervalo , entonces la densidad uniforme contínua es:
La notación se lee: x se distribuye uniforme contínua en el intervalo a,b
- Valor esperado de la distribución uniforme continua
- Varianza de la distribución uniforme continua
Ejemplo: Contaminante (contento, pg. 198)
La concentración de cierto contaminante está distribuida de manera uniforme en el intervalo a ppm. Si se considera tóxica una concentración de o más, responda las preguntas:
-
¿Con qué probabilidad al tomarse una muestra se encuentra una concentración tóxica?
-
¿Cuál es la concentración media? ¿la varianza?
-
¿Con qué probabilidad la concentración es exactamente ?
Ejemplo: Probabilidad lineal
Supongamos que la densidad de probabilidad está dada por la siguiente función:
Representada por la siguiente gráfica:
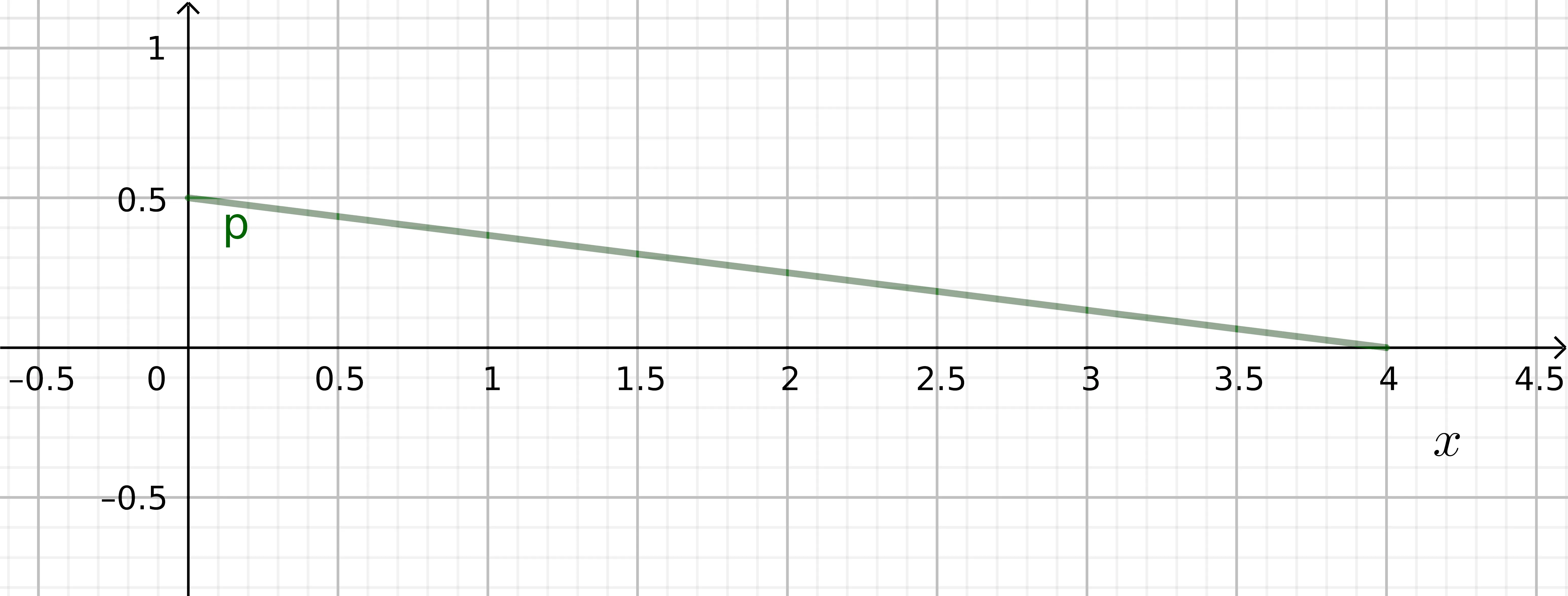 Si quisieramos hallar la probabilidad de que la variable tome valores entre 0 y 1, por ejemplo, se requiere la integral:
Si quisieramos hallar la probabilidad de que la variable tome valores entre 0 y 1, por ejemplo, se requiere la integral:
La probabilidad de que la variable tome valores entre y es de
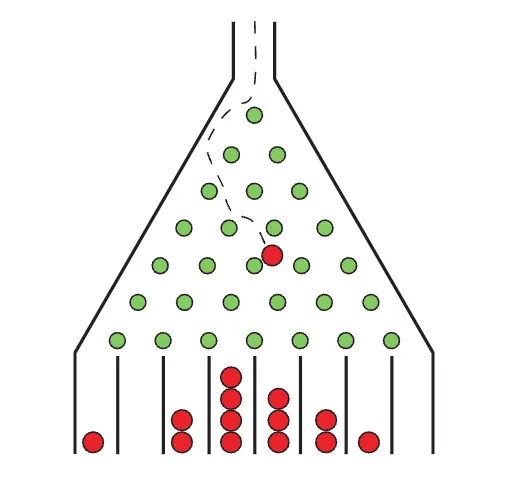
Distribución binomial (repaso)
Supongamos que se lanza una moneda 100 veces, y se registra el resultado como +1 si se obtiene cara y -1 si se obtiene sello. Nos preguntamos:
-
¿Qué valores se pueden obtener en la suma?
-
¿Qué valor es más probable?
-
¿Que características tiene la distribución de probabilidad de la variable “suma”?
Podemos decir que se trata de una distribución binomial. Los valores que puede tomar la suma van de -100 (si todas son sellos) a +100 (si todas son caras. La situación más probable es que la suma sea 0, es decir que haya tantos valores de cara como de sello. Y sabemos que la distribución será simétrica, es decir la probabilidad de que la suma sea igual a 1 es idéntica a que sea -1, y así sucesivamente.
Distribución gaussiana (normal)
Existen variables continuas que tienen características similares a las de la binomial. Es el caso de las variables morfológicas (forma). Si pensamos por ejemplo en el peso al nacer de neonatos de una misma generación, se espera que el valor más común sea el promedio, y que a medida que nos alejamos del promedio se reduzca la probabilidad.
La distribución gaussiana tiene las siguientes características:
-
Está definida por dos parámetros, que son su promedio y su desviación estándar .
-
La variable es un continua:
-
La distribución es simétrica
-
Su mediana es igual a su moda
-
Asintótica al eje x (se acerca a cero).
-
Tiene la siguiente forma funcional:
Aquí es la desviación estándar, el promedio. Es una función exponencial. (Ayuda: aunque parece rara, usualmente se calcula con computadoras.)
-
Distribución Gaussiana Estandar: Para simplificar la forma funcional y poder realizar cálculos sin computadora, se ha estudiado la Gaussina que tiene , . Es:
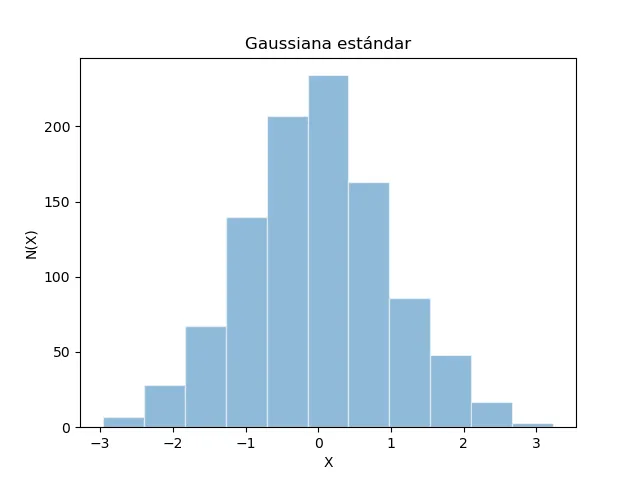
Simulación de la distribución gaussiana
Se usa la función random.normalde la librería numpy. En la ayuda
se tienen tres argumentos: loc, scale y size: normal(loc=0.0, scale=1.0, size=None). Corresponden al centro de la distribución,
; la desviación estándar, y el tamaño de la muestra
. La distribución gaussiana ** estandar** tiene y . Por ejemplo:
import numpy as np
muestra = np.random.normal(0,1,1000)
plt.hist(muestra,bins=11,edgecolor='w',alpha=0.5)
plt.xlabel("X")
plt.ylabel("N(X)")
plt.title("Gaussina estandar")
Se obtiene la siguiente gráfica:
Ejercicio en clase, diferentes distribuciones gaussianas.
Seguimos con .
-
Haga una gráfica que tenga tres simulaciones. Las muestras deben ser gaussianas con , pero centradas respectivamente en , y .
-
Haga una gráfica que tenga tres simulaciones. Las muestras deben ser gaussianas con , pero con diferentes valores de la varianza, , y . Incluya la variable
density=Trueen el plot:plt.hist( ... ,density=True). Ojo, esta instrucción está incompleta, debe reemplazar los...por las instrucciones que usted conoce.
Estandarización
Es un proceso para comparar distribuciones que tienen diferentes parámetros, pero que tienen la misma forma. Recordemos que la forma funcional de la gaussiana es ; fíjese que la variable aparece acompañada de y de la forma . La estandarización consiste en definir una nueva variable :
El valor determina la distancia, medida en desviaciones estándar, desde el promedio. Es positiva si está a la derecha del promedio y negativa si está a su izquierda.
Por la forma que tiene la distribución gaussiana, Z usualmente varía entre -3 hasta 3; es decir de 3 desviaciones estándar a la izquierda hasta 3 desviaciones estándar a la derecha.
Ejemplo, comparando resultados de dos exámenes
(fuente: Diez, D. M., Barr, C. D., & Cetinkaya-Rundel, M. (2012). OpenIntro statistics, página 134)
Supongamos que tenemos dos poblaciones a las que se les hacen exámenes diferentes, pero que tratan de medir lo mismo. Pueden ser exámenes saber 11 de dos años diferentes, que tratan de evaluar lo mismo pero resultan que en la práctica uno es más difícil que el otro. ¿cómo se pueden comparar los resultados personas que hicieron diferentes examenes?
-
Ana tiene un puntaje sin estandarizar de 370, y en su grupo el promedio fue de 350 con una desviación estándar de 20.
-
Juan tiene un puntaje sin estandarizar de 370, en su grupo el promedio fue de 360, con una desviación estándar de 5.
Cómo se puede comparar el puntaje de Ana con el de Juan?
La gráfica muestra distribución del grupo de Ana, en naranja; y la distribución del grupo de Juan, en azul.
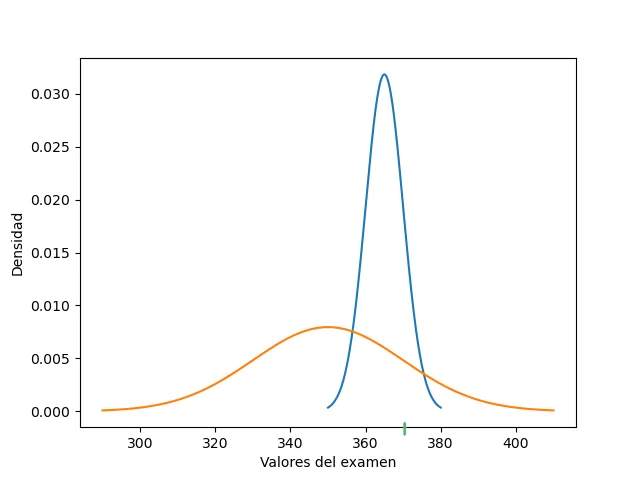
Aunque ambos tuvieron el mismo puntaje sin estandarizar, hay una mayor variabilidad en el grupo de Ana que en el grupo de Juan. Para compararlos usamos el valor .
Ambos están a la derecha del promedio, pero Ana está sólo a una desviación estándar del promedio; mientras que Juan está a dos desviaciones estándar del promedio. En comparación a sus grupos, es decir a las situaciones que les correspondió a cada uno, por ejemplo en términos de que tan difícil fue su examen, Juan tiene una mejor valoración que Ana.
Tabla Gaussiana Estandar
Reporta las probabilidades acumuladas hasta un dado. Es decir, calcula . Es el área de la siguiente gráfica.
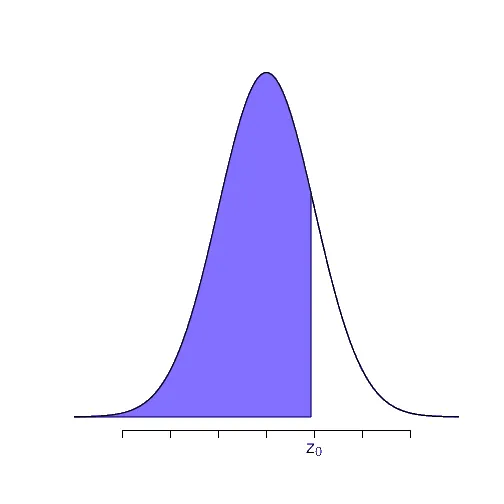
Ejemplo
Supongamos que queremos encontrar la probabilidad de que la variable tenga un valor menor a . Eso equivale a encontrar el área bajo la curva desde hasta . Esa área correspondería gráficamente a la siguiente área marcada con violeta:
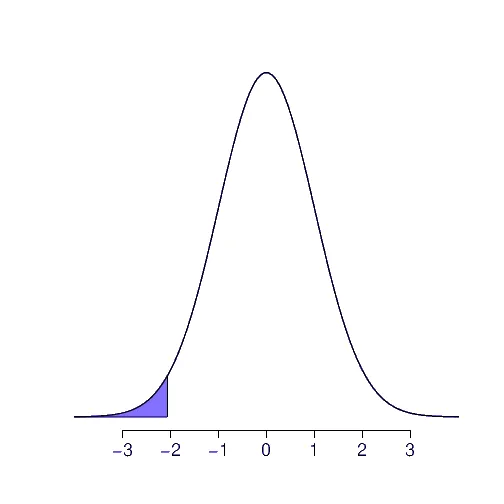
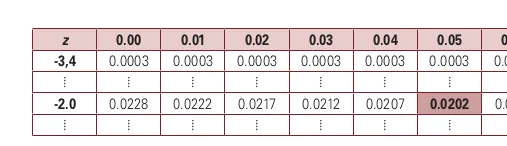
Para encontrar esta probabilidad con el software se usa la tabla. Se buscan las unidades y el primer decimal en la primera columna y el segundo decimal en la primera fila, así:
Probabilidad a cola derecha
La probabilidad a cola derecha corresponde al área acumulada a partir de un valor. Por ejemplo, la siguiente figura representa la probabilidad :
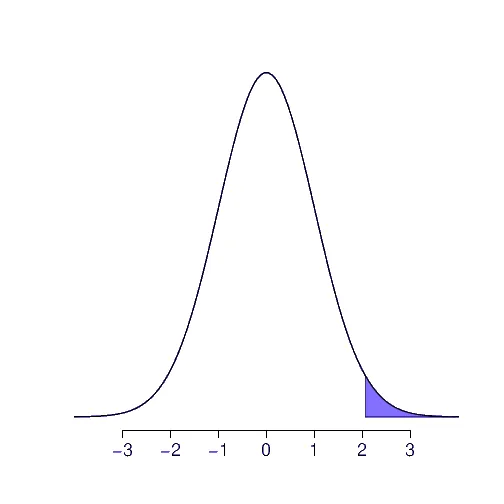
Ahora, en las tablas está la probabilidad a cola izquierda. Luego lo que se hace es buscar el evento complementario , y calcular su probabilidad. El complemento del evento es el evento:
Luego:
En Python
Se importa la librería statsde scipy:
import scipy.stats as st
Por ejemplo, para la probabilidad acumulada , se haría:
st.norm.cdf(-2.05)
Lo que da el valor: 0.020182215405704394, se puede aproximar a cuatro decimales en 0.0202.
Para :
1-st.norm.cdf(2)
Se obtiene 0.02275013194817921 o aproximando a cuatro decimales 0.0227.
Punto crítico
Es el valor tal que la probabilidad . Se representa en la siguiente gráfica por el valor
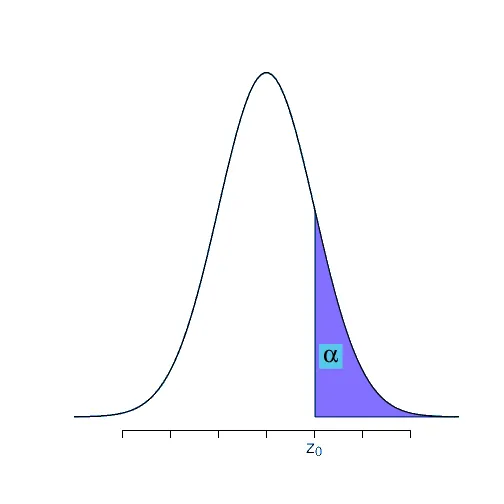
Es decir, si antes teníamos el valor y hallabamos la probabilidad , ahora tenemos la probabilidad a cola derecha y buscamos el valor .
Para hacerlo usando la tabla de probabilidades, como la tabla tiene probabilidad a cola izquierda y aquí queremos a cola derecha, usamos la probabilidad del evento complementario. Es decir buscamos en la tabla el valor que corresponde a la probabilidad .
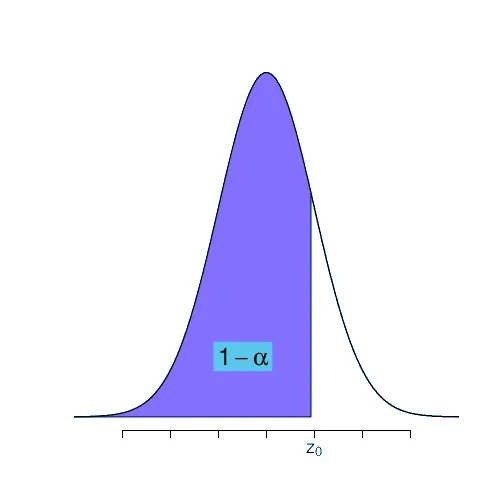
Ejemplo
¿Que hace que ?
Tomamos
Según la tabla:

El valor sería de -1. Este es un valor aproximado, si se calcula con el software se tiene:
st.norm.ppf(0.1587)
Lo que devuelve el valor .
Bibliografía
-
la imágen de la máquina de Galton está en mathoverlow: https://mathoverflow.net/questions/419706/placing-pins-on-a-galton-board-to-approximate-an-arbitrary-distribution
-
La función ppf de scipy.stats https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.rv_continuous.ppf.html
-
La función cdf de scipy.stats https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.rv_continuous.cdf.html
-
Ejemplo en stackoverflow https://stackoverflow.com/questions/20864847/probability-to-z-score-and-vice-versa