Table of contents
Open Table of contents
Visualización
¿Para Qué? ¡Atención!
¿Para Qué?
- Profundizar nuestra comprensión de la estructura de los datos
- Hallar datos atípicos (outliers)
- Exponer posibles explicaciones (data-storytelling)
- Evite las gráficas y
- Simplifique. Evite usar efectos gráficos sólo por (como efectos 3D)
- Haga uso adecuado de las . Prefiera relación de aspecto 1 a 1 e incluir el 0.
Descripción de los datos
Tipos de Datos
- Series de tiempo
- Univariados / Multivariados
- Redes

Características de los Datos
- Categóricos 🔶, 🟩, 🔵, 🔺
- Ordenados: Ordinales o Cuantitativos
- Órden:
- Secuenciales ➡️
- Divergentes ↔️
- Cíclicos 🔃
Estructuras (o estructurar) los datos
- Tablas
- Redes o árboles
- Organizados geométricamente o en listas, o en agrupamientos
Tipos de Representación
- Gráficos de Dispersión
- Histogramas
- Redes / Grillas / Tablas
- Árboles

Preparación
Revisión de la Documentación
- CodeBook
Preparación
- Cargar pandas
import pandas as pd - Cargar seaborn
import seaborn as sns
- Cargar los datos
pd.read
- Averiguar el número de variables y de registros
df.shape(27555, 4602) - Averiguar el nombre de las variables
df.columns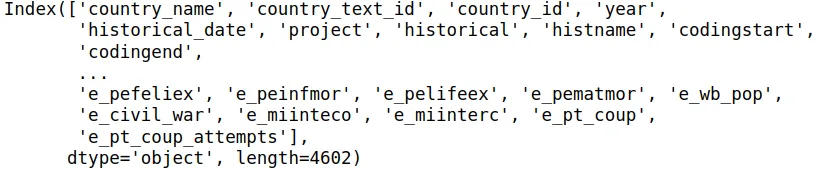
- Leer las primeras columnas
df.head(5), las últimasdf.tail(5), o una muestradf.sample(5)
Describiendo las distribuciones
# de registros por valores de Variable categórica

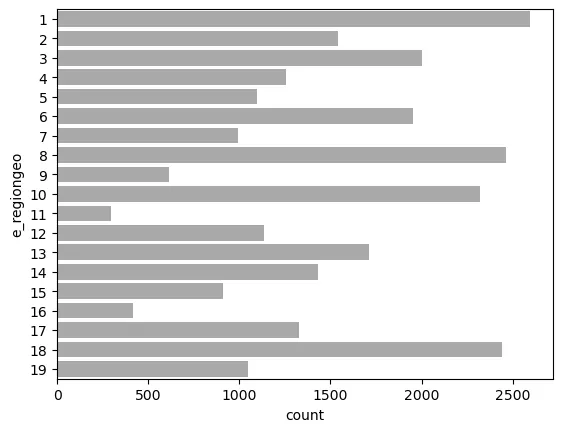
Usando el diccionario que habíamos definido antes:
region={1:'Western Europe',2:'Northern Europe',
3:'Southern Europe', 4:'Eastern Europe',5:'Northern Africa',
6:'Western Africa', 7:'Middle Africa',8:'Eastern Africa',
9:'Southern Africa',10:'Western Asia',11:'Central Asia',
12:'East Asia',13:'South-East Asia',14:'South Asia',
15:'Oceania',16:'North America',17:'Central America',
18:'South America', 19:'Caribbean'}`
Podemos reemplazar:
df.replace({'e_regiongeo': region}, inplace=True)
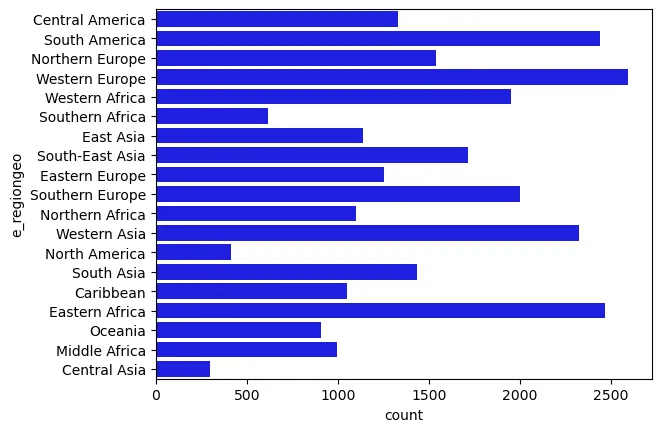
# regiones por valores de variable categórica
ax = sns.countplot(data=df, y='e_regiongeo',color='darkgray')
ax = sns.countplot(data=df, y='e_regiongeo',color='blue')
Ejercicio
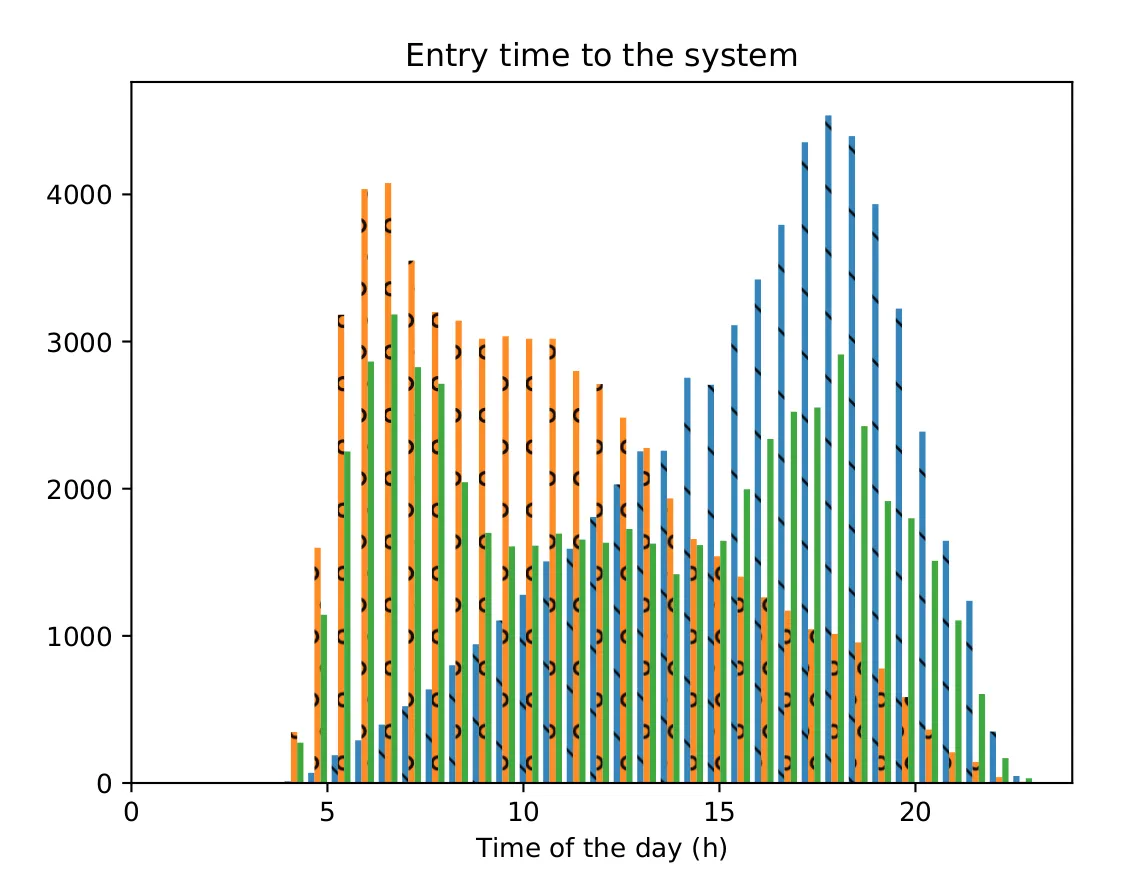
Vamos a trabajar con los datos de Nacimientos del DANE del 1998
- Vaya a la página del DANE, busque el directorio de datos. Allí trabaje sobre la variable
tipo_parto - Haga una gráfica que tenga el número de registros por los diferentes valores de la variable
tipo_parto - Cree un diccionario para cambiar los valores de
tipo_partopor las palabras a las que corresponce - Aplique el directorio para que la gráfica muestre las palabras.
- Repita el procedimiento para alguna otra variable de interés.
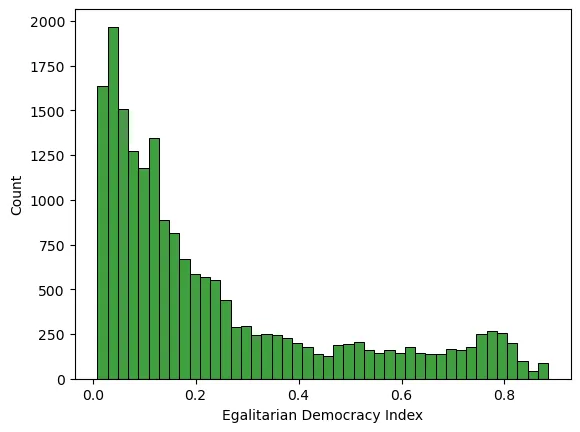
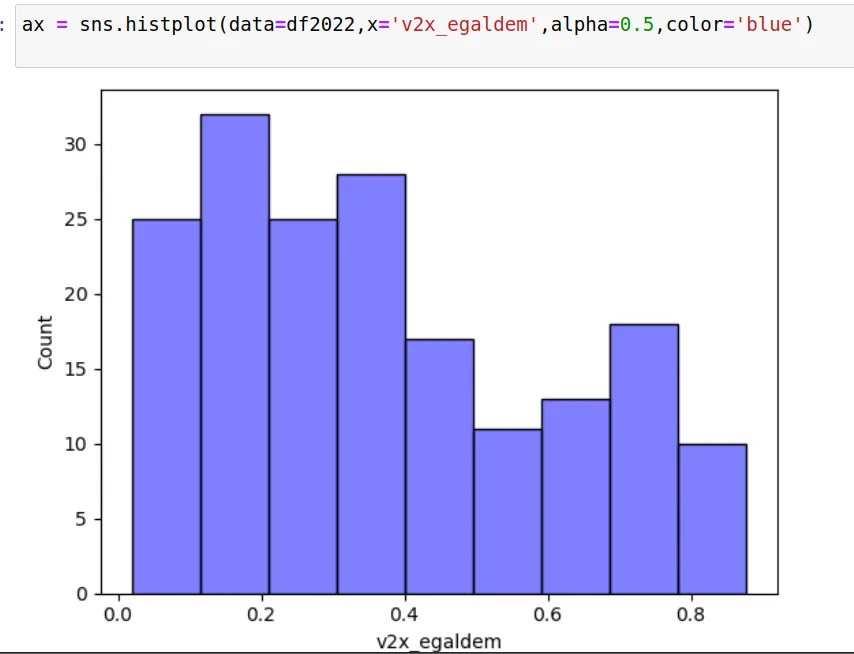
Histogramas de una variable

A continuación nombramos los ejes:
ax.set(xlabel='Egalitarian Democracy Index',ylabel='Count')
Ejercicio
- Utilice la base V Dem 1
- Identifique los datos correspondientes al año 2022, con el vector
filtro20222 - Genere un
DataFramecon los datos del año 2022,df20223 - También identifique los de 1900, y genere un
DataFramecon ellos,df19004 - Genere un histograma del índice de democracia igualitaria del año 1900, en verde.5
- Genere un histograma del índice de democracia igualitaria del año 2022, en azul. 6
- ¿Qué se le ocurre que puede decir al comparar las dos distribuciones?
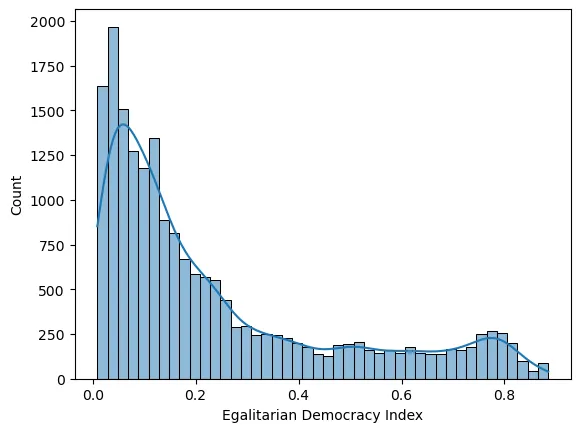
Histogramas de una variable, con estimación de densidad

Por ejemplo, para el índice de democracia igualitaria:
ax.set(xlabel='Egalitarian Democracy Index',ylabel='Count')
Se obtiene la figura:
\eb
Análisis Multivariado
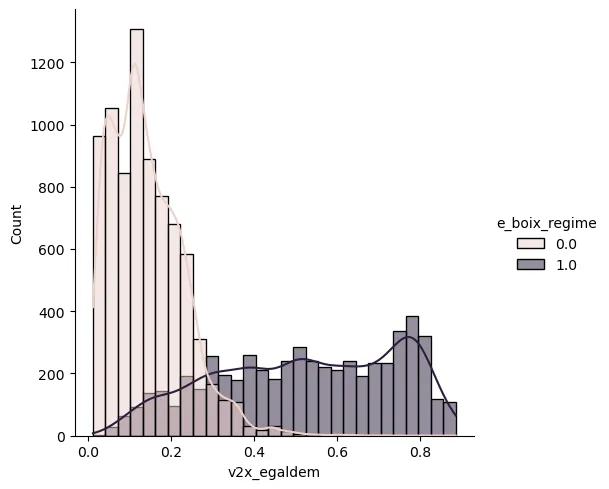
Histogramas Condicionados
Para generar el histograma condicionado se usa la siguiente instrucción:

Con:
ax.set(xlabel='Egalitarian Democracy Index')
Se obtiene:
Diagramas de Dispersión

Se añade el título a los ejes:
ax.set(xlabel=‘Egalitarian Democracy Index’,ylabel=‘Polyarchy Index’)
Y se obtiene la gráfica:
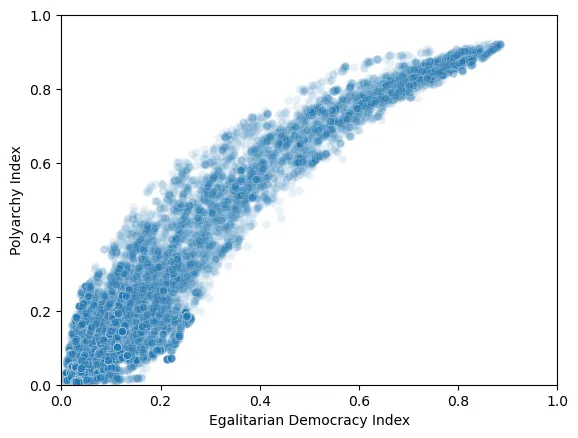
Se puede profundizar en éstos temas en la bibliografía.7
Ejercicio
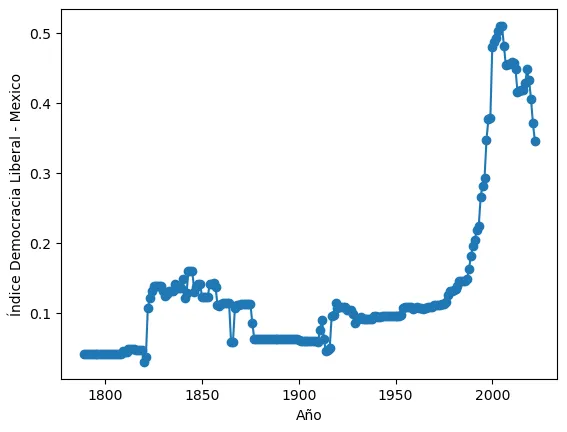
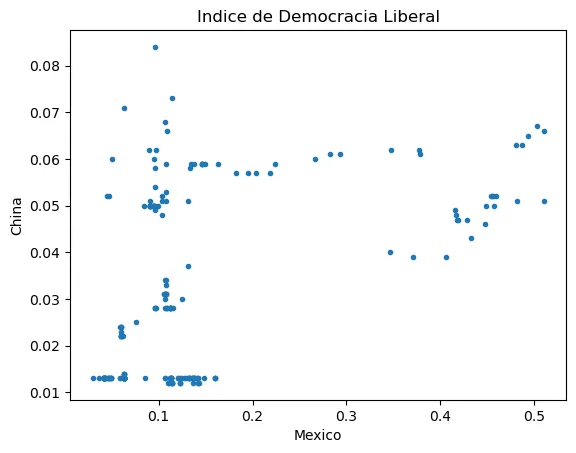
- Genere un diagrama de dispersión en el que se comparen el índice de democracia electoral y el índice de democracia igualitaria entre el año 2022 y el año 1900.8
- ¿qué puede decir sobre la evolución de la democracia entre 1900 y 2022?
Referencias
Gráficas
* Traveling Salesmen (Red) https://networkx.org/documentation/stable/auto_examples/drawing/plot_tsp.html#sphx-glr-auto-examples-drawing-plot-tsp-py
* Harvest https://matplotlib.org/stable/gallery/images_contours_and_fields/image_annotated_heatmap.html#sphx-glr-gallery-images-contours-and-fields-image-annotated-heatmap-py
* Random Graph https://networkx.org/documentation/stable/auto_examples/drawing/plot_random_geometric_graph.html#sphx-glr-auto-examples-drawing-plot-random-geometric-graph-py
Footnotes
-
Se importan las librerías. Pandas:
import pandas as pdY seaborn:import seaborn as snsY se carga el dataframedf = pd.read_csv("V-Dem-CY-Full+Others-v13.csv")↩ -
Se filtran con
rowfilter:rowfilter = df['year'] == 2022Con esta órden sólo lo creamos, no imprimimos. Para revisar podríamos, por ejemplo, calcular la suma:print(sum(rowfilter))↩ -
df2022 = df[rowfilter]↩ -
Creamos el filtro:
rowfilter1900 = df['year'] == 1900. Filtramos:df1900 = df[rowfilter1900]↩ -
Así:
 ↩
↩ -
Así:
 ↩
↩ -
Específicamente:
- Histogramas bivariados: McLevey pg.195
- Estimación Kernel bivariada: McLevey pg.198
- Ajuste: McLevey pg. 200 y 203
-
El diagrama es el siguiente:
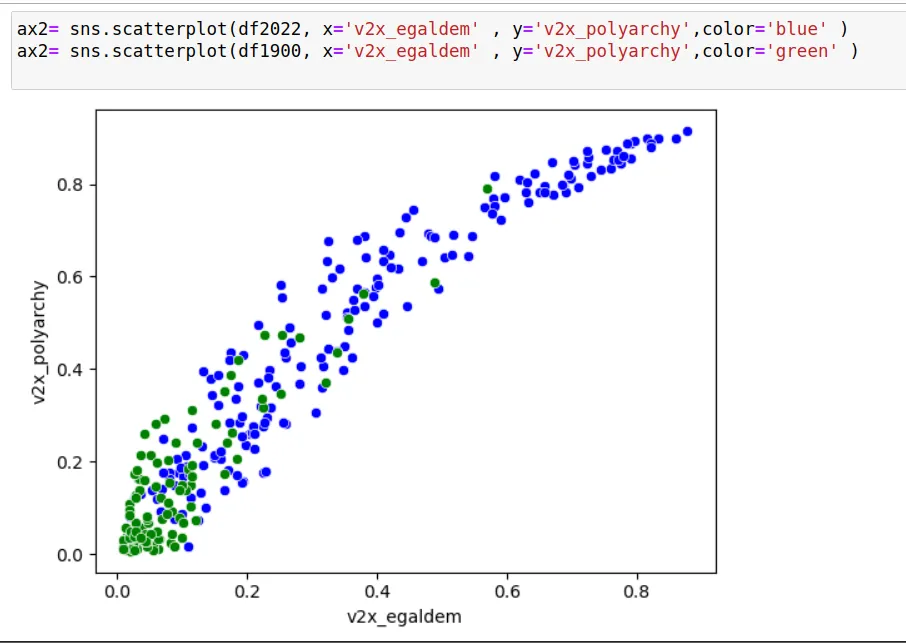 ↩
↩